Vapor(三)数据库篇
作为一个服务器,没有比数据库更重要的东西,在Vapor上有多种数据库提供选择,而且已经有良好的封装和中间件,简单的调用就能访问到数据库,同时横向兼容。
这篇文章讲解了Vapor中和数据库相关的一些配置、操作、原理等的内容。
数据库选型
MySQL 和 PostgreSQL 的对比,网上已经很多分析,例如这篇PostgreSQL 与 MySQL 相比,优势何在?。为了感受一下潮流,我选择了PostgreSQL来学习和练习。
DatabaseKit
Connection
DatabaseKit主要负责创建、管理和合并连接。又了连接我们才能访问数据库,而创建连接对应用来说是一件非常耗时的任务,以至于很多云服务都会限制一个服务能打开的连接数,关于性能方面的知识可以自行去了解。参考1 参考2
由路由传入request来请求连接时,如果连接池中没有可用的连接则创建一条新连接,若连接数达到了上限则等待被释放放回的连接。
再观察一下Request实现的协议
public final class Request: ContainerAlias, DatabaseConnectable, HTTPMessageContainer, RequestCodable, CustomStringConvertible, CustomDebugStringConvertible其中就是DatabaseConnectable决定Request拥有连接数据库的能力
// 请求一条连接池中的连接,连到 `.psql` db
req.withPooledConnection(to: .psql) { conn in
return conn.query(...) // do some db query
}上面方法中的闭包会在req请求到有效连接时回调,而当闭包返回的Future完成时,此连接则会自动释放回连接池。
如果你想手动请求一条连接,就要对应地手动释放此条连接
// Request a connection from the pool and wait for it to be ready.
let conn = try app.requestPooledConnection(to: .psql).wait()
// Ensure the connection is released when we exit this scope.
defer { app.releasePooledConnection(conn, to: .psql) }可以配置连接数据库的连接池
// Create a new, empty pool config.
var poolConfig = DatabaseConnectionPoolConfig()
// Set max connections per pool to 8.
poolConfig.maxConnections = 8
// Register the pool config.
services.register(poolConfig)为了避免竞争的状况出现,连接池绝对不能在事件循环之间共享使用。通常一个连接池对应一个数据库和一个事件循环。意味着应用打开指定数据库的连接数为 线程数 * 池中的最大连接数。
还可以单独地创建连接,但必须注意的是,不要在路由的回调闭包中这样使用,因为频繁的访问会导致创建出很多连接,而由路由回调闭包返回的连接则是从连接池中获取的。
// Creates a new connection to `.sqlite` db 。同样,使用闭包返回连接的形式能够在回调时自动释放连接,只是这里不是释放到池中而已。
app.withNewConnection(to: .sqlite) { conn in
return conn.query(...) // do some db query
}
// Creates a new connection to `.sqlite` db 。 需手动释放连接。
let conn = try app.newConnection(to: .sqlite).wait()
// Ensure the connection is closed when we exit this scope.
defer { conn.close() }Logging
配置数据库日志功能
// Enable logging on the SQLite database
dbsConfig.enableLogging(for: .sqlite)
//或
// Create a custom log handler.
let myLogger: DatabaseLogHandler = ...
// Enable logging on SQLite w/ custom logger.
dbsConfig.enableLogging(for: .sqlite, logger: myLogger)Keyed Cache
键缓存,是可通过键来获取、设置和移除Codable值的操作方式,有时会称作键值储存。
要创建一个键缓存,需要用到Container协议中的方法.keyedCache(for:)
// Creates a DatabaseKeyedCache with .redis connection pool
let cache = try app.keyedCache(for: .redis)
// Sets "hello" = "world"
try cache.set("hello", to: "world").wait()
// Gets "hello"
let world = try cache.get("hello", as: String.self).wait()
print(world) // "world"
// Removes "hello"
try cache.remove("hello").wait()Redis
Redis是一个事件驱动、无阻塞、建立于SwiftNIO的库。可以通过发送Redis的命令与服务端直接交互,又或者通过Vapor的KeyedCache接口来当作缓存使用。
配置Redis
//SPM
let package = Package(
name: "MyApp",
dependencies: [
// ⚡️Non-blocking, event-driven Redis client.
.package(url: "https://github.com/vapor/redis.git", from: "3.0.0"),
],
targets: [
.target(name: "App", dependencies: ["Redis", ...])
]
)
//configure.swift
import Redis
// register Redis provider
try services.register(RedisProvider())首先创建连到Redis数据库的新连接,
router.get("redis") { req -> Future<String> in
return req.withNewConnection(to: .redis) { redis in
// send INFO command to redis and map the resulting RedisData to a String
return redis.command("INFO").map { $0.string ?? "" }//单行的略简语法
}
}Get/Set/Delete命令,通过这对命令可以在服务端(使用key:value的形式)存储、提取和删除对应的数据,可以传入任何Codable类型的数值。
router.get("set") { req -> Future<HTTPStatus> in
// create a new redis connection
return req.withNewConnection(to: .redis) { redis in
// save a new key/value pair to the cache
return redis.set("hello", to: "world")
// convert void future to HTTPStatus.ok
.transform(to: .ok)
}
}
router.get("get") { req -> Future<String> in
// create a new redis connection
return req.withNewConnection(to: .redis) { redis in
// fetch the key/value pair from the cache, decoding a String
return redis.get("hello", as: String.self)
// handle nil case
.map { $0 ?? "" }
}
}
router.get("del") { req -> Future<HTTPStatus> in
// create a new redis connection
return req.withNewConnection(to: .redis) { redis in
// fetch the key/value pair from the cache, decoding a String
return redis.delete("hello")
// convert void future to HTTPStatus.ok
.transform(to: .ok)
}
}也可将Redis作为Vapor KeyedCache协议的后端
router.get("set") { req -> Future<HTTPStatus> in
let string = try req.query.get(String.self, at: "string")
return try req.keyedCache(for: .redis).set("string", to: string)
.transform(to: .ok)
}
router.get("get") { req -> Future<String> in
return try req.keyedCache(for: .redis).get("string", as: String.self)
.unwrap(or: Abort(.badRequest, reason: "No string set yet."))
}Fluent
Fluent 是一个构建ORMs(Object Relational Mapping 对象关系映射)的框架,通过Fluent能够整合多种数据库,但它本身并不是ORM,它需要数据库来驱动才能运作,最初的Fluent也是为了整合构建NoSQL和SQL两种数据库做而诞生。
数据库驱动(Database Driver)可以有多个选择,比如 MySQL、SQLite、MongoDB、PostgreSQL。
Vapor 2.0对应的版本
在Vapor2.0的时候,Driver是通过Provider来封装的,然后Vapor直接使用Provider来操作数据库,例如PostgreSQLProvider
import PackageDescription
let package = Package(
name: "OneVideo-Vapor",
dependencies: [
.Package(url: "https://github.com/vapor/vapor.git", majorVersion: 2),
.Package(url: "https://github.com/vapor/fluent-provider.git", majorVersion: 1), //可独立于Vapor使用
//.Package(url: "https://github.com/vapor/fluent.git", majorVersion: 2),
.Package(url: "https://github.com/vapor/postgresql-provider.git", majorVersion: 2, minor: 0) ],
exclude: [ ... ]
)FluentProvider(fluent-provider/fluent)相当于一套标准接口,提供给Vapor使用,作用就是上面交代的整合数据库、构建数据库。PostgreSQLProvider(postgresql-provider,它会再依赖postgresql)则是Fluent接口与驱动postgresql的适配器、中间件,即按Fluent的标准提供由postgresql操作数据库的接口,而Vapor无感知。
若想直接使用PostgreSQL,不使用Fluent的情况下则
import PackageDescription
let package = Package(
name: "Project",
dependencies: [
...
.Package(url: "https://github.com/vapor/postgresql.git", majorVersion: 2)
],
exclude: [ ... ]
)Vapor 3.0对应的版本
大致上与2.0的操作套路一样,只是库包的名称有所变化,同样拿PostgreSQL举例
// swift-tools-version:4.0
import PackageDescription
let package = Package(
name: "MyApp",
dependencies: [
/// Any other dependencies ...
.package(url: "https://github.com/vapor/fluent-postgresql.git", from: "1.0.0"),
],
targets: [
.target(name: "App", dependencies: ["FluentPostgreSQL", ...]),
.target(name: "Run", dependencies: ["App"]),
.testTarget(name: "AppTests", dependencies: ["App"]),
]
)以前的Provider/Driver叫做了FluentPostgreSQL(仍然会依赖postgresql),这样命名更清晰直观,一看就知道是遵循Fluent的驱动,后半部分的命名则是具体驱动的数据库类型。
但不一定每个Driver都有Provider,也不一定每个Driver的Provider都满足最新版本的Vapor,具体要看社区在Vapor使用某种数据库的贡献程度。
如果只想引用PostgreSQL而不用Fluent的话,则
let package = Package(
name: "MyApp",
dependencies: [
// 🐘 Non-blocking, event-driven Swift client for PostgreSQL.
.package(url: "https://github.com/vapor/postgresql.git", from: "1.0.0"),
],
targets: [
.target(name: "App", dependencies: ["PostgreSQL", ...]),
...
]
)Model
使用模型去查询数据库,返回的结果是确定类型的集合,而不像其它ORM语言返回的是不确定类型的集合。不同的数据库驱动提供了其对应的便利模型,例如PostgreSQLModel。
1.定义一个模型
//必须使用final修饰,也可以定义得更通配 final class User<D>: Model where D: Database
final class User: Model {
/// See `Model.Database`。指定数据库,使Fluent可以动态地添加合适的方法和数据类型到`QueryBuilder`,若使用通配的方式定义模型时应写成 typealias Database = D
typealias Database = FooDatabase
/// See `Model.ID`。指定ID的类型
typealias ID = Int
/// See `Model.idKey`。指定ID属性的KeyPath,且必须指向一个Optional类型的属性。
static let idKey: IDKey = \.id
/// The unique identifier for this user. 模型的唯一标识,即ID属性
var id: Int?
var name: String
var age: Int
/// Creates a new user. 必须实现的初始化方法
init(id: Int? = nil, name: String, age: Int) {
self.id = id
self.name = name
self.age = age
}
}Fluent 3 就是这样设计成让我们可以通过模型和驱动的联系来驾驭数据库的力量。
2.模型的生命周期方法
- willCreate
- didCreate
- willUpdate
- didUpdate
- willRead
- willDelete
final class User: Model {
/// ...
/// See `Model.willUpdate(on:)`
func willUpdate(on connection: Database.Connection) throws -> Future<Self> {
/// Throws an error if the username is invalid
try validateUsername()
/// Return the user. No async work is being done, so we must create a future manually.
return Future.map(on: connection) { self }
}
}3.增删改查(CRUD)
CRUD (create, read, update, delete)
//在模型的数据库中增加一条记录,当模型没有ID时调用.save(on:)会转为调用该方法
//若模型为值类型(struct)的时候,.create(on:)返回的模型会带上新的ID
let didCreate = user.create(on: req)
print(didCreate) /// Future<User>
///找出ID == 1的那个模型
let user = User.find(1, on: req)
print(user) /// Future<User?>
///找出所有name为"Vapor"的模型
let users = User.query(on: req).filter(\.name == "Vapor").all()
print(users) /// Future<[User]>
///更新模型,如果已经有ID则在调用.save(on:)时会转为调用该方法
let didUpdate = user.update(on: req)
print(didUpdate) /// Future<User>
///删除模型
let didDelete = user.delete(on: req)
print(didDelete) /// Future<Void>
///获取唯一的ID或抛出异常
let id = try user.requireID()要查询数据,首先要连接数据库,最简单的连接方式就是使用路由返回的Request,它会使用模型的defaultDatabase属性作为连接目标,然后自动抓取一个合并了该数据库的连接。你也可以在Container容器上使用便利方法来手动创建连接。详细的查询方法在下面的 PostgreqSQL一节再作介绍。但是暂时还不支持Union查询。
Migration
然后在Vapor3.0的Fluent里还增加了一个叫Migration的概念,其实就是一个可使模型的属性被动态识别的协议(建立属性与数据表各字段的关联),不一定必须扩展Model类型。默认情况下,只要也遵循Model协议Fluent就能自动推断出模型各属性及其类型并实现了prepare和revert方法
//User.swift
import FluentPostgreSQL
import Vapor
final class User: PostgreSQLModel {
typealias Database = PostgreSQLDatabase
typealias ID = Int
var id: ID?
var name: String
init(id: ID? = nil, name: String) {
self.id = id
self.name = name
}
}
extension User: PostgreSQLMigration { }
//configure.swift
var migrations = MigrationConfig()
migrations.add(model: User.self, database: .psql)
services.register(migrations)其它情况下可以重写prepare方法在准备创建数据表前通过builder声明及创建自定义需要的字段,或在revert方法中删除废弃的字段或数据表。
//User.swift
extension User: PostgreSQLMigration {
//访问数据表前执行
static func prepare(on conn: PostgreSQLConnection) -> Future<Void> {
//创建数据表
return PostgreSQLDatabase.create(User.self, on: conn) { builder in
builder.field(for: \.id, isIdentifier: true)
builder.field(for: \.name)
//try builder.field(for: \.name, type: <#DataType#>) //指定字段的类型
}
//结合判断发布的版本的逻辑,更新已有数据表的字段
return PostgreSQLDatabase.update(User.self, on: conn) { builder in
builder.field(for: \.mass) //当然模型需要新增上这个属性
builder.deleteField(for: \.name)
}
//根据条件修改操作
return Galaxy.query(on: conn).filter(\.mass == 0).delete()
}
//启动应用时执行
static func revert(on connection: PostgreSQLConnection) -> Future<Void> {
return PostgreSQLDatabase.delete(User.self, on: connection)
//直接返回一个预先完成的future
return conn.future(())
}
}
//configure.swift
var migrations = MigrationConfig()
migrations.add(migration: CreateGalaxy.self, database: .psql)
services.register(migrations)注意,设置自定义的Migration需要使用add(migration:database:)这个方法。
Relation
Fluent支持两种关系模型,分别是单对多(父-子 parent-child)和多对多(同辈 siblings)。
单对多示例
//父模型
extension Galaxy {
// this galaxy's related planets
var planets: Children<Galaxy, Planet> {
return children(\.galaxyID)
}
}
//子模型
extension Planet {
// this planet's related galaxy
var galaxy: Parent<Planet, Galaxy> {
return parent(\.galaxyID)
}
}
let galaxy: Galaxy = ...
let planets = galaxy.planets.query(on: ...).all()//即是在Planet中查出含该galaxy的ID的模型
let planet: Planet = ...
let galaxy = planet.galaxy.get(on: ...)//直接查出planet对应的galaxy(根据planet中的galaxy的ID)多对多示例
struct PlanetTag: Pivot {
// ...
typealias Left = Planet
typealias Right = Tag
//利用对应的keyPath,指定关系的依据
static var leftIDKey: LeftIDKey = \.planetID
static var rightIDKey: RightIDKey = \.tagID
var id: Int?
var planetID: Int
var tagID: Int
}
extension Planet {
// this planet's related tags ,<From, To, Through>
var tags: Siblings<Planet, Tag, PlanetTag> {
return siblings()
}
}
extension Tag {
// all planets that have this tag ,<From, To, Through>
var planets: Siblings<Tag, Planet, PlanetTag> {
return siblings()
}
}
let planet: Planet = ...
planet.tags.query(on: ...).all()
//提供中途插入关系的方法
extension PlanetTag: ModifiablePivot {
init(_ planet: Planet, _ tag: Tag) throws {
planetID = try planet.requireID()
tagID = try tag.requireID()
}
}
let planet: Planet = ...
let tag: Tag = ...
planet.tags.attach(tag, on: ...)Transaction
事务,在其未完成前,数据不会被保存到数据库。
var userA: User = ...
var userB: User = ...
return req.transaction(on: .<#dbid#>) { conn in
return userA.save(on: conn).flatMap { _ in
return userB.save(on: conn)
}.transform(to: HTTPStatus.ok)
}上面的例子表示,只要userA或userB有一个save失败,则均不会保存到数据库。事务一完成,结果就会转换成HTTP的状态响应。
PostgreSQL
PostgreSQL 是建立在 SwiftNIO 库之上的一个纯Swift库。它比 Fluent ORM 低一级,是Provider和Driver的主要功能实现者,但独立于封装它的Fluent Provider/Driver。即使是这样,PostgreSQL 还扩展了DatabaseKit的连接池和交互接口、Vapor的服务架构。
当你有以下条件或需求时,可以跨过Provider/Driver直接使用它
- 拥有非标准结构的数据库
- 依赖于复杂或重度自定义的SQL语句查询
- 不喜欢ORM
但这里以FluentPostgreSQL介绍PostgreSQL的应用。
先将环境搭建然后在项目中引用之。
安装与启动
//安装postgresql
brew install postgresql
//开启postgresql方式一
brew services start postgresql
//开启postgresql方式二
pg_ctl -D /usr/local/var/postgres start
//开启postgresql方式三
postgres -D /usr/local/var/postgres/
//关闭postgresql
pg_ctl -D /usr/local/var/postgres stop -s -m fast配置
//配置数据存放目录
initdb /usr/local/var/postgres -E utf8
//配置开机启动postgresql
ln -sfv /usr/local/opt/postgresql/*.plist ~/Library/LaunchAgents
launchctl load ~/Library/LaunchAgents/homebrew.mxcl.postgresql.plist
createuser username -P
#Enter password for new role:
#Enter it again:使用
//创建数据库
createdb [-U username] dbname
//删除数据库
dropdb [-U username] dbname
//创建数据库并指定拥有者和编码格式(及显示操作指令)
createdb dbname -O username -E UTF8 -e
//查看已创建的数据库
psql -l
//连接数据库
psql dbname //使用默认用户连接(当前Mac账号登入)
psql -U username -d dbname -h 127.0.0.1
psql (9.6.2)
Type "help" for help.
//显示已创建的数据库
dbname=# \l
//连接数据库
dbname=# \c dbname
//显示数据库表
dbname=# \d
//退出当前的数据库连接
dbname=# \q
//创建表(并指定拥有者)
dbname=# CREATE TABLE test(id int, text VARCHAR(50)) [ OWNER [ = ] user_name ];
//插入记录
dbname=# INSERT INTO test(id, text) VALUES(1, 'sdfsfsfsdfsdfdf');
//查询记录
dbname=# SELECT * FROM test WHERE id = 1;
//更新记录
dbname=# UPDATE test SET text = 'xx' WHERE id = 1;
//删除记录
dbname=# DELETE FROM test WHERE id = 1;
//删除表
dbname=# DROP TABLE test;
//删除数据库
dbname=# DROP DATABASE dbname;详细可参考
PostgreSQL新手入门
PostgreSQL 结构及权限
管理
下载pgAdmin4,添加数据库到pgAdmin4前应先确认账号和数据库均已创建好。
添加Server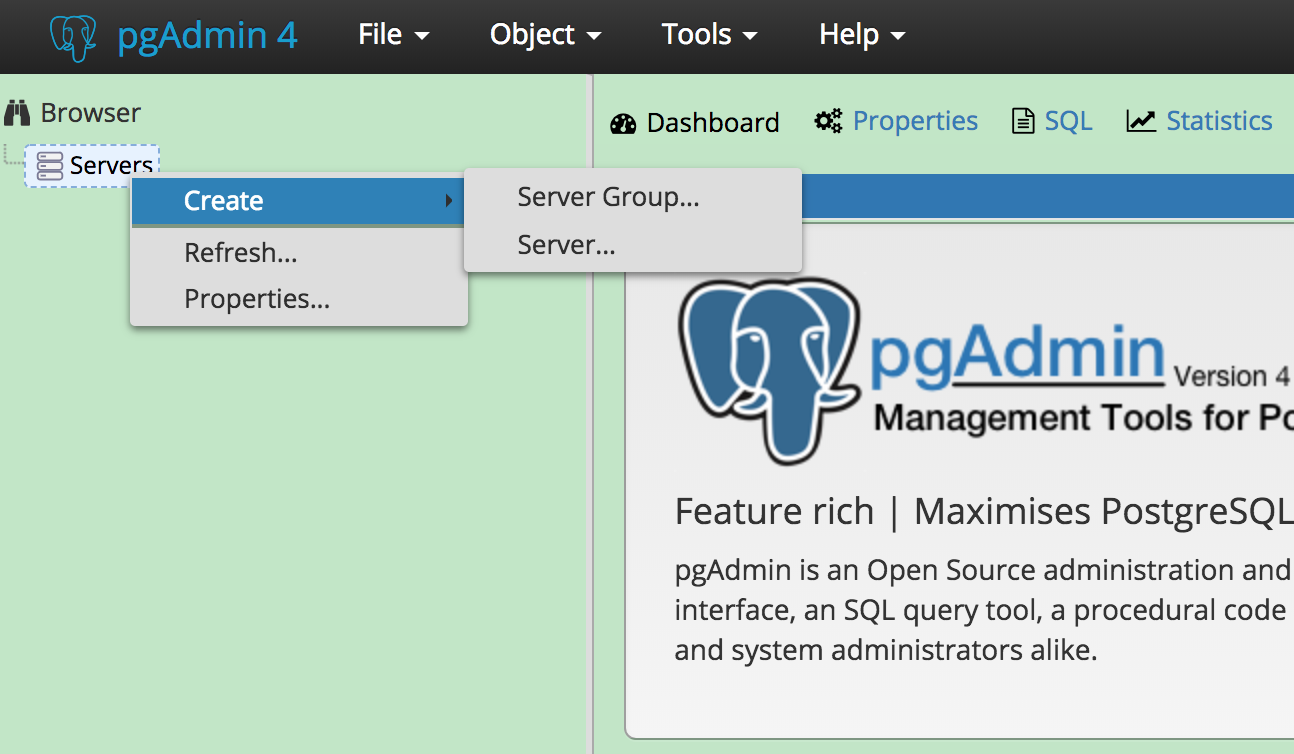
指定Server的数据库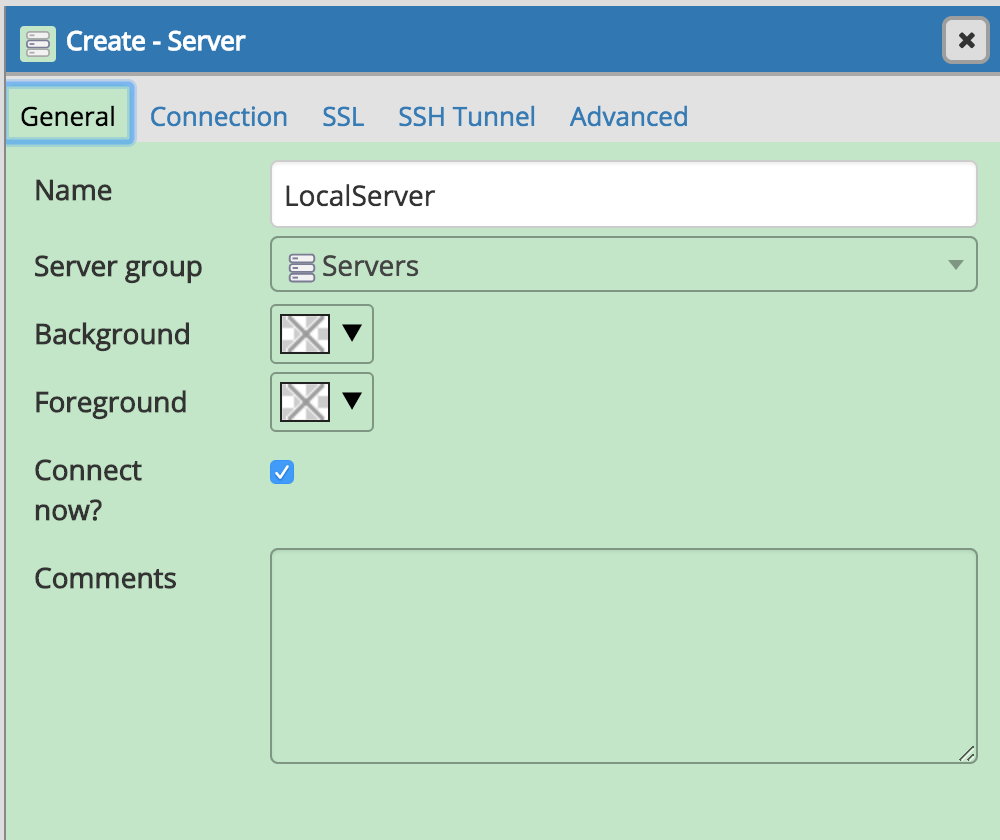
查看数据表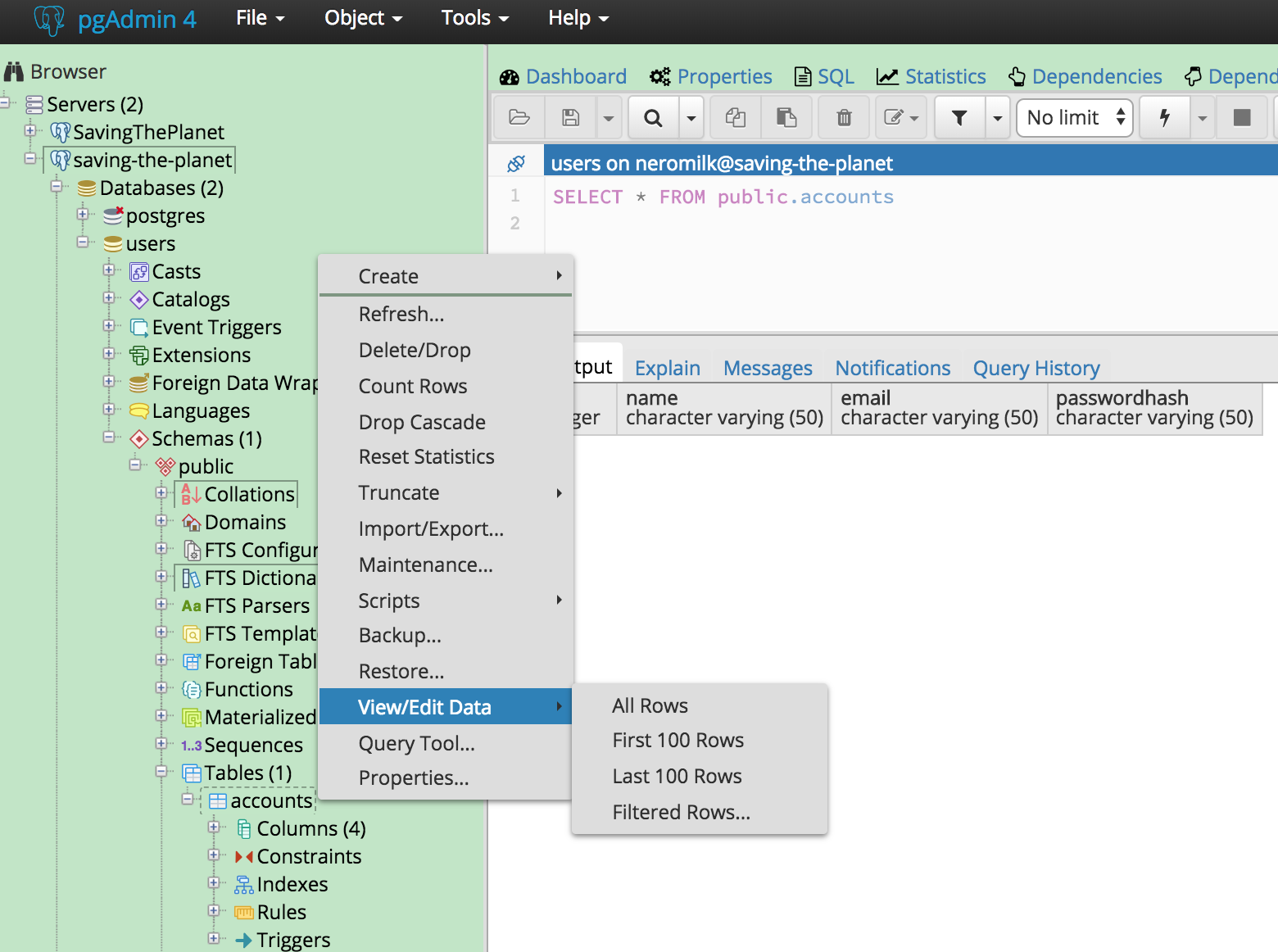
安装后会在这个地址中 http://127.0.0.1:49707/browser/ 启动 pgAdmin4。
应用
上述的步骤完成后,意味着我们搭建好了使用PostgreSQL的环境。而要使用它还需要在项目中进行配置,
注册服务
//in configure.swift.
import FluentPostgreSQL
import Vapor
// Register providers first
try services.register(FluentPostgreSQLProvider())
// 若不使用Fluent的注册如下
try services.register(PostgreSQLProvider())添加数据库配置
// Configure a PostgreSQL database. 这里无论是直接使用PostgreSQL还是Fluent,都是一样的配置方式
let postgreSql = PostgreSQLDatabase(config: PostgreSQLDatabaseConfig(hostname: "localhost", username: "xx"))
/// Register the configured PostgreSQL database to the database config.
var databases = DatabasesConfig()
databases.add(database: postgresql, as: .psql)
services.register(databases)数据库操作
//保存一个模型对象,返回带ID、默认值字段的模型对象
router.post("galaxies") { req in
let galaxy: Galaxy = ...
//注意,req是实现了DatabaseConnectable协议的对象,在该参数中扮演的角色实质是connection链接,这一句的代码描述应该是:“将模型通过连接创建到数据库中去”
return galaxy.create(on: req)
}
//查找
Galaxy.find(42, on: conn)
Galaxy.find(42, on: conn).unwrap(or: Abort(...))
Galaxy.query(on: conn).filter(\.name == "Milky Way")
Galaxy.query(on: conn).filter(\.mass >= 500).filter(\.type == .spiral)//前后的filter链形成与的关系
Galaxy.query(on: conn).group(.or) {
$0.filter(\.mass <= 250).filter(\.mass >= 500)
}.filter(\.type == .spiral)//选择filter链的关系
Galaxy.query(on: conn).range(..<50)
Galaxy.query(on: conn).sort(\.name, .descending)
Galaxy.query(on: conn).join(\Planet.galaxyID, to: \Galaxy.id)
.filter(\Planet.name == "Earth") //合并表查找,找出所有planet name为Earth的galaxy(Planet的表合并到Galaxy后,在Galaxy新增的Planet属性中过滤)
(join and filter).alsoDecode(Planet.self).all()//对筛选的结果转换回合并前的模型编码,使用(Galaxy, Planet)元祖类型返回。
Galaxy.query(on: conn).all()
Galaxy.query(on: conn).range(..<50).all()
Galaxy.query(on: conn).chunk(max: 32) { galaxies in
print(galaxies) // Array of 32 or less galaxies
}
Galaxy.query(on: conn).filter(\.name == "Milky Way").first()
//更新
var planet: Planet ... // fetched from database
planet.name = "Earth"
planet.update(on: conn)
//删除
var planet: Planet ... // fetched from database
planet.delete(on: conn)若不使用 Fluent 的情况(是的,会麻烦点),则
struct PostgreSQLVersion: Codable {
let version: String
}
router.get("sql") { req in
return req.withPooledConnection(to: .psql) { conn in
return conn.raw("SELECT version()")
.all(decoding: PostgreSQLVersion.self)
}.map { rows in
return rows[0].version
}
}SQL
最后,看看SQL的应用,它在Vapor里是一个独立的库(vapor/sql),提供了在Swift中的序列化SQL查询功能,实现的主要协议包括DQL、DML、DDL,上面介绍的组件均基于它来实现查询。
支持的查询有
- SELECT, INSERT, UPDATE, DELETE
- CREATE TABLE, ALTER TABLE, DROP TABLE
- CREATE INDEX, DROP INDEX
例如SELECT这个方法,它支持
- , columns, and expressions like functions
- FROM
- JOIN
- GROUP BY
- ORDER BY
SELECT * FROM "users" WHERE "users"."name" = ?对应的vapor/sql实现就是
struct User: SQLTable, Codable {
static let sqlTableIdentifierString = "users"
let id: Int?
let name: String
}
router.get("sql") { req in
return req.withPooledConnection(to: .psql) { conn in
let users = conn.select()
.all().from(User.self)
.where(\User.name == "Vapor")
.all(decoding: User.self)
print(users) // Future<[User]>
return users// use conn to perform a query
}
}转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 mingfungliu@gmail.com
文章标题:Vapor(三)数据库篇
文章字数:4.8k
本文作者:Mingfung
发布时间:2018-08-15, 21:33:00
最后更新:2018-09-04, 23:23:14
原始链接:http://blog.ifungfay.com/后端/Vapor(三)数据库篇/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

