Android工程入门
深入了解很多Android工程上的内容时,产生了很多疑惑,由于时间实在分不开来,本身没有先系统地学习,都是针对不懂的查查问问,所以这里算是来一个Android工程入门的杂谈吧(其实叫杂烩比较合乎),记录一些收集到的原理和方法、一些自己的观点和遇到的问题。
工程结构
Project与Module的区别
Project相当于Eclipse里面的工作区间,Module相当于Eclipse里面的project。AS里面的项目结构也可以像Eclipse一样,一个Project新建多个Module。
一般的组件化管理下,都会在Project中建多个板块功能Module,App也作为其中一个Module来管理。Project中的build.gradle具有全局性,若Module的build.gradle与Project的有重复且冲突项,则以Project的为准。
第三方库引用
- project structure->app->Dependencies->”+”->Library dependency->Search->OK(自动build)
- 切换为Project树结构->app/libs->放入jar包->Build
- project structure->app->Dependencies->”+”->Module dependency->选择Module->OK(自动build)
- build.gradle(Module:app)->dependencies->compile/implementation ‘package:name:ver’,本地aar用implementation(name:’filename’,ext:’aar’)
- 复制各架构的so到app/libs->build.gradle(Module:app)添加到android下sourceSets {main {jniLibs.srcDirs =[‘libs’]}}->Build(其实是为了兼容以往eclipse路径,类似的还有 res.srcDirs)
- 直接复制各架构的so到app/src/main/jniLibs
Gradle
语法上是基于Groovy语言(基于JVM的敏捷开发语言,可以简单的理解为强类型语言Java的弱类型版本),在项目管理上是基于Ant(Java编译器)和Maven概念的项目自动化建构工具。
Android多Moudule(也就是gradle中的多Project Multi-Projects Build)的基本项目结构:
├── app #Android App目录
│ ├── app.iml
│ ├── build #构建输出目录
│ ├── build.gradle #构建脚本
│ ├── libs #so相关库
│ ├── proguard-rules.pro #proguard混淆配置
│ └── src #源代码,资源等
├── module #Android 另外一个module目录
│ ├── module.iml
│ ├── build #构建输出目录
│ ├── build.gradle #构建脚本
│ ├── libs #so相关库
│ ├── proguard-rules.pro #proguard混淆配置
│ └── src #源代码,资源等
├── build
│ └── intermediates
├── build.gradle #工程构建文件
├── gradle
│ └── wrapper
├── gradle.properties #gradle的配置
├── gradlew #gradle wrapper linux shell脚本
├── gradlew.bat
├── LibSqlite.iml
├── local.properties #配置Androod SDK位置文件
└── settings.gradle #工程配置Gradle多个Project的例子:
├── app
│ ├── build.gradle #构建脚本
├── module
│ ├── build.gradle #构建脚本
├── build.gradle #工程构建文件
├── gradle
│ └── wrapper #先不去管它
├── gradle.properties #gradle的配置
├── gradlew #gradle wrapper linux shell脚本
├── gradlew.bat
└── settings.gradle #工程配置build.gradle是Gradle默认的构建脚本文件,执行Gradle命令的时候,会默认加载当前目录下的build.gradle脚本文件。
每次构建至少由一个project构成,一个project由一到多个task构成。项目结构中的每个build.gradle文件代表一个project,在这编译脚本文件中可以定义一系列的task;task 本质上又是由一组被顺序执行的Action对象构成,Action其实是一段代码块,类似于Java中的方法。
执行流程
- 和Maven一样,Gradle只是提供了构建项目的一个框架,真正起作用的是Plugin。
- Gradle在默认情况下为我们提供了许多常用的Plugin,其中包括有构建Java项目的Plugin,还有Android等。
- 与Maven不同的是,Gradle不提供内建的项目生命周期管理,只是java Plugin向Project中添加了许多Task,这些Task依次执行,为我们营造了一种如同Maven般项目构建周期。
- Gradle是一种声明式的构建工具。在执行时,Gradle并不会一开始便顺序执行build.gradle文件中的内容,而是分为两个阶段,第一个阶段是配置阶段,然后才是实际的执行阶段。
- 配置阶段,Gradle将读取所有build.gradle文件的所有内容来配置Project和Task等,比如设置Project和Task的Property,处理Task之间的依赖关系等。
- Gradle为每个build.gradle都会创建一个相应的Project领域对象,在编写Gradle脚本时,我们实际上是在操作诸如Project这样的Gradle领域对象。在多Project的项目中,我们会操作多个Project领域对象。Gradle提供了强大的多Project构建支持。
- 要创建多Project的Gradle项目,我们首先需要在根(Root)Project中加入名为settings.gradle的配置文件,该文件应该包含各个子Project的名称。Gradle中的Project可以简单的映射为AndroidStudio中的Module。
- 在最外层的build.gradle。一般干得活是:配置其他子Project的。比如为子Project添加一些属性。
每次构建的执行本质上是执行一系列的task,并且某些task还需要依赖其他task,这些task的依赖关系都是在构建阶段确定的。每次构建分为3个阶段:
- Initialization: 初始化阶段
- 这是创建Project阶段,构建工具根据每个build.gradle文件创建出一个Project实例。初始化阶段会执行项目根目录下的settings.gradle文件,来分析哪些项目参与构建。
- Configuration:配置阶段
- 这个阶段,通过执行构建脚本来为每个project创建并配置Task。配置阶段会去加载所有参与构建的项目的build.gradle文件,会将每个build.gradle文件实例化为一个Gradle的project对象。然后分析project之间的依赖关系,下载依赖文件,分析project下的task之间的依赖关系。
- Execution:执行阶段
- 这是Task真正被执行的阶段,Gradle会根据依赖关系决定哪些Task需要被执行,以及执行的先后顺序。task是Gradle中的最小执行单元,我们所有的构建,编译,打包,debug,test等都是执行了某一个task,一个project可以有多个task,task之间可以互相依赖。例如我有两个task,taskA和taskB,指定taskA依赖taskB,然后执行taskA,这时会先去执行taskB,taskB执行完毕后在执行taskA。在AS右侧的Gradle按钮中可以看到这一些列的task
build.gradle文件分析
apply plugin: 'com.android.application'
android {
compileSdkVersion 25
buildToolsVersion "25.0.0"
defaultConfig {
applicationId "me.febsky.demo"
minSdkVersion 15
targetSdkVersion 25
versionCode 1
versionName "1.0"
testInstrumentationRunner "android.support.test.runner.AndroidJUnitRunner"
}
buildTypes {
release {
minifyEnabled false
proguardFiles getDefaultProguardFile('proguard-android.txt'), 'proguard-rules.pro'
}
}
}
dependencies {
compile fileTree(dir: 'libs', include: ['*.jar'])
compile 'com.android.support:appcompat-v7:25.1.0'
}- 方法调用,圆括号可以省略
- 如果方法参数是个Map,方括号可以省略
- 闭包作为函数的最后一个参数,可以在括号内或括号外,没括号时不用关注
- Groovy动态的为每一个字段都会自动生成getter和setter,并且我们可以通过像访问字段本身一样调用getter和setter。
所以上面的apply plugin: 'com.android.application',可以看成是apply([plugin: 'com.android.application'])
Gradle的Project之间的依赖关系是基于Task的,而不是整个Project的。
Project:是Gradle最重要的一个领域对象,我们写的build.gradle脚本的全部作用,其实就是配置一个Project实例。在build.gradle脚本里,我们可以隐式的操纵Project实例,比如,apply插件、声明依赖、定义Task等,如上面build.gradle所示。apply、dependencies、task等实际上是Project的方法,参数是一个代码块。如果需要,也可以显示的操纵Project实例,比如:project.ext.myProp = ‘myValue’
Task:Gradle中的Task要么是由不同的Plugin引入的,要么是我们自己在build.gradle文件中直接创建的。Gradle保证Task按照依赖顺序执行,并且每个Task最多只被执行一次。
dependencies:在Project的gradle dependencies 中使用classpath一般是指添加buildscript本身需要运行的东西。buildScript是用来加载gradle脚本自身需要使用的资源,可以声明的资源包括依赖项、第三方插件、maven仓库地址等。 在App的gradle dependencies 中添加应用程序所需要的依赖包,也就是项目运行所需要的东西。
- 项目根目录的 build.gradle 文件:用来配置针对所有模块的一些属性。它默认包含2个代码块:buildscript{…}和allprojects{…}。前者用于配置构建脚本所用到的代码库和依赖关系,后者用于定义所有模块需要用到的一些公共属性
- settings.gradle 文件:会在构建的 initialization 阶段被执行,它用于告诉构建系统哪些模块需要包含到构建过程中。对于单模块项目, settings.gradle 文件不是必需的。对于多模块项目,如果没有该文件,构建系统就不能知道该用到哪些模块。
- 模块级配置文件 build.gradle :针对每个moudle 的配置,如果这里的定义的选项和顶层 build.gradle定义的相同。它有3个重要的代码块:plugin,android 和 dependencies。
Task示例
task myTask {
doFirst {
println 'hello'
}
doLast {
println 'world'
}
}这段代码的含义是给Project添加一个名为“myTask”的任务。用一个闭包来配置这个任务,Task提供了doFirst和doLast方法来给自己添加Action。
其实build.gradle脚本的真正作用,就是配置一个Project实例。在执行build脚本之前,Gradle会为我们准备好一个Project实例,执行完脚本之后,Gradle会按照DAG依次执行任务。
如果task声明在根Project的build.gradle中的allprojects()方法中,那么这个Task会应用于所有的Project。
如果是Muliti-Project的模式,依赖关系要带着所属的Project,如taskA.dependsOn ‘:other-project:taskC’ 其中taskC位于和taskA不同的Project中,相对于AndroidStudio来说,就是位于不同的Module下的build.gradle中,而other-project为Module名字。
其它实现
自定义Plugin:每一个自定义的Plugin都需要实现Plugin接口,除了给Project编写Plugin之外,我们还可以为其他Gradle类编写Plugin。该接口定义了一个apply()方法,在该方法中,我们可以操作Project,比如向其中加入Task,定义额外的Property等。
Gradle Wrapper:顾名思义,其实就是对Gradle的一层包装,便于在团队开发过程中统一Gradle构建的版本,然后提交到git上,然后别人可以下载下来,这样大家都可以使用统一的Gradle版本进行构建,避免因为Gradle版本不统一带来的不必要的问题。(所以要明白这个东西可以没有,有了只是为了统一管理,更加方便)
子Module的依赖展开:这样做的目的是为给其它子Module或者给父Project也能引用存在于当前子Module中的依赖libs。在根工程(即父Project)下的build.gradle中添加如下代码,核心部分是repositories中的flatDir
allprojects {
repositories {
jcenter()
flatDir {
dirs project(':sub_module').file('libs')
}
}
}BuildConfig
程序编译成功后,会在每一个 Module 的 build/generated/sources/buildConfig/debug(或 release)/包名(此处包名是针对 Module 的 Manifest 上的 package)文件夹下生成一个 BuildConfig 类,应用代码通过这个类可以获取跟 Gradle 构建有关的信息。例如通过 BuildConfig.DEBUG 就可以判断当前是否处于 debug 模式,来控制日志输出。并且官方提供了 buildConfigField() 方法,将自定义字段添加到 Gradle 构建配置文件的 BuildConfig 类中,可采用这种方式去配置 SDK 版本号。
buildConfig.java 示例:
package com.module.demo;
public final class BuildConfig {
public static final boolean DEBUG = Boolean.parseBoolean("true");
public static final String APPLICATION_ID = "com.module.demo";
public static final String BUILD_TYPE = "debug";
public static final int VERSION_CODE = 1;
public static final String VERSION_NAME = "1.0";
public BuildConfig() {
}
}** flavor 赋值 **
android {
......
productFlavors{
某厂 {
}
}
......
}public final class BuildConfig {
...
public static final String FLAVOR = "某厂";
...
}** 自定义字段 **
android {
......
buildType {
debug {
buildConfigField "String","BASE_URL","\"http://www.test.com/\""
buildConfigField "int","DATE","20160701"
}
release {
buildConfigField "String","BASE_URL","\"http://www.release.com/\""
buildConfigField "int","DATE","20160702"
}
}
}public final class BuildConfig {
...
// 如果是 release 模式下打的包则 BASE_URL = "http://www.release.com/"
public static final String BASE_URL = "http://www.test.com/";
public static final int DATE = 20160701;
...
}相关函数
Gradle plugin 3.0依赖方式增加了 implementation 和 api ,用以取代 compile。
有工程 A、B、C.让 A 依赖 B (implementation、api 都可以)。
若B implementation C,则 A 不能调用 C 的方法。
若 B api C,则 A 可以调用 C 的方法(同 compile)。
实用例子
构造jar
task makeJar(type: Jar, dependsOn: ['assembleRelease']) {
destinationDir = file('build/outputs/libs')
baseName = "some-sdk"
version = project.ext.mCurVersion // 版本号
from(zipTree('build/intermediates/aar_main_jar/release/classes.jar'))
exclude('com/efn/testapp/util/BuildConfig.class')
}
task clearJar(type: Delete) {
delete "build/lib"
}更新硬编码的版本号
// 编译前版本号更新
preBuild.dependsOn updateVersion
task updateVersion {
def versionFileDir = projectDir.getAbsolutePath() + "/src/main/java/com/xx/yy.java"
def oldVersionStr = findOldVersionStr(versionFileDir)
def newVersionValue = project.ext.mCurVersion
def newVersionStr = " private static final String VERSION = \"" + newVersionValue + "\";"
def updatedContent = new File(versionFileDir).getText('UTF-8').replaceAll(oldVersionStr, newVersionStr)
new File(versionFileDir).write(updatedContent, 'UTF-8')
}
def static findOldVersionStr(path) {
def readerString = ""
new File(path).withReader('UTF-8') { reader ->
reader.eachLine {
if (it.contains("private static final String VERSION = ")) {
readerString <<= it
return readerString
}
}
return readerString
}
}aar自动命名
// android下
buildTypes {
release {
...
android.libraryVariants.all{
variant->
variant.outputs.all{
outputFileName = "xxx-${project.name}-${project.ext.mCurVersion}.aar"
}
}
}
}打包选项
// android下
packagingOptions {
// 过滤掉不加入apk(但不能过滤aar和jar里的内容)
exclude 'META-INF/**'
exclude 'lib/arm64-v8a/libmediaplayer.so'
// 匹配的第一个加入apk(但不能匹配aar和jar里的内容)
pickFirst "lib/armeabi-v7a/libaaa.so"
// 设置动态库不被优化压缩(被优化压缩过了可能其md5受影响,如oaid库不能被识别)
doNotStrip "*/armeabi/*.so"
// 匹配的都加入apk
merge '**/LICENSE.txt'
}签名
// android 下
signingConfigs {
release {
keyAlias 'xxx'
keyPassword 'yyy'
storeFile file('../keystore/abc.keystore')
storePassword 'yyy'
}
debug {
// 同上
...
}
}
buildTypes {
release {
...
signingConfig signingConfigs.release
}
}Maven
抽取公共Gradle的实现
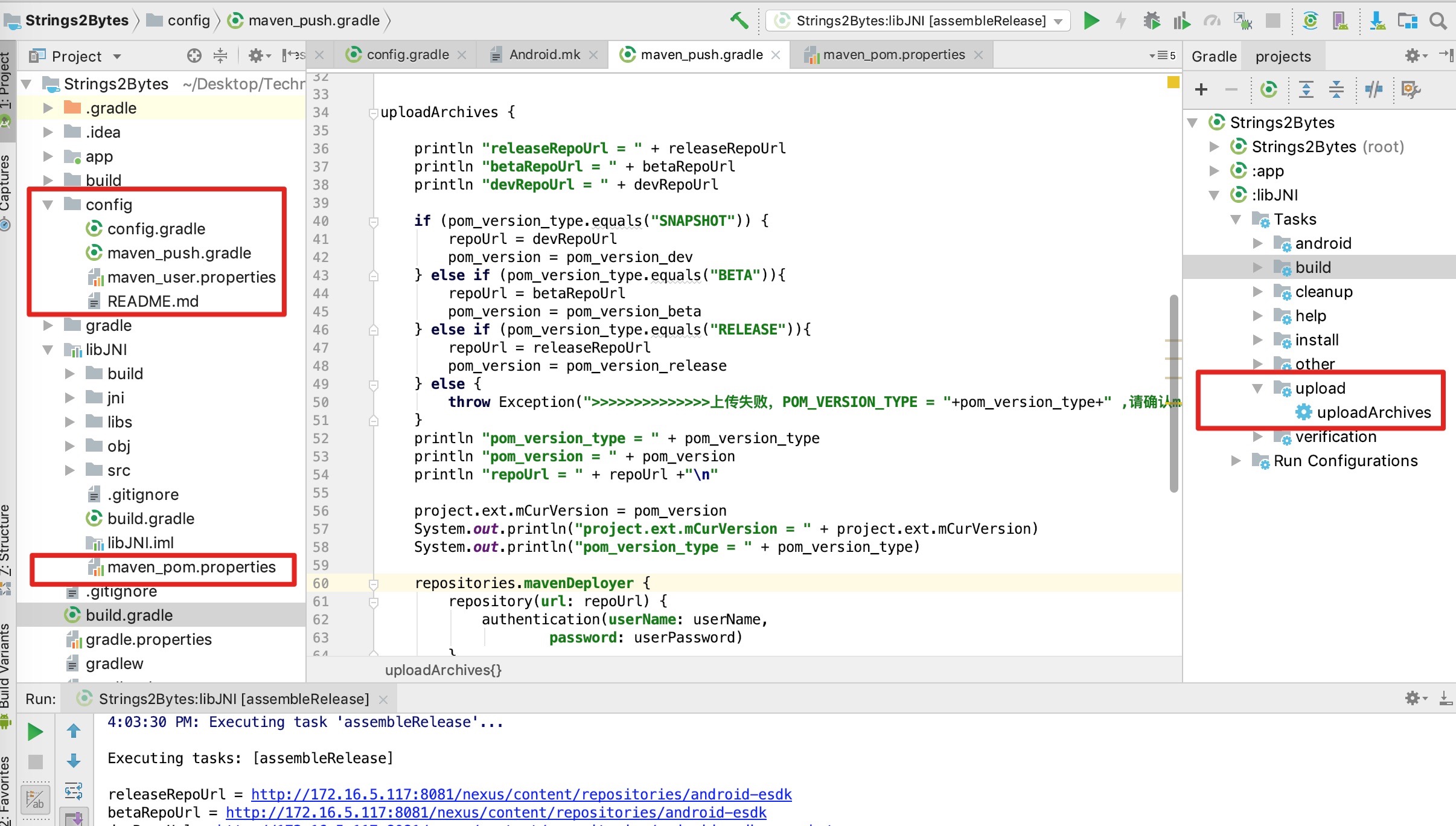
在组件化的环境上应用Maven时,应将各个Module共有的关于Maven的配置和gradle脚本实现抽取。
上图是将公共的Maven配置和脚本进行入库,每个Module需要应用Maven时就从git上clone它下来作为当前Module的子模块。
maven_user.properties是存放通用的Maven配置(像Maven仓库的地址、帐密等),而maven_pom.properties是存放Module的Maven配置(可在工程中直接新建一个File,自定义后缀为.properties即可创建,包括像Module名称、描述、Maven组ID、打包方式、版本号等)
工程导入这些gradle脚本后,像图中右侧的gradle栏中就会出现相关Task,包括默认的和自定义的(upload-uploadArchives就是maven_push.gradle中定义和实现的)
ProGuard
是AS SDK里自带的工具,主要作用是混淆代码,但包括以下4个功能:
- 压缩(Shrink):检测并移除代码中无用的类、字段、方法和特性(Attribute)。
- 优化(Optimize):对字节码进行优化,移除无用的指令。
- 混淆(Obfuscate):使用a,b,c,d这样简短而无意义的名称,对类、字段和方法进行重命名。
- 预检(Preveirfy):在Java平台上对处理后的代码进行预检,确保加载的class文件是可执行的。
压缩环节会检测以及移除没有用到的类、字段、方法以及属性。优化环节会分析以及优化方法的字节码。混淆环节会用无意义的短变量去重命名类、变量、方法。这些步骤让代码更精简,更高效,也更难被逆向(破解)。
工作原理
ProGuar由shrink、optimize、obfuscate和preveirfy四个步骤组成,每个步骤都是可选的,我们可以通过配置脚本来决定执行其中的哪几个步骤。
混淆就是移除没有用到的代码,然后对代码里面的类、变量、方法重命名为人可读性很差的简短名字。
那么有一个问题,ProGuard怎么知道这个代码没有被用到呢?
这里引入一个Entry Point(入口点)概念,Entry Point是在ProGuard过程中不会被处理的类或方法。在压缩的步骤中,ProGuard会从上述的Entry Point开始递归遍历,搜索哪些类和类的成员在使用,对于没有被使用的类和类的成员,就会在压缩段丢弃,在接下来的优化过程中,那些非Entry Point的类、方法都会被设置为private、static或final,不使用的参数会被移除,此外,有些方法会被标记为内联的,在混淆的步骤中,ProGuard会对非Entry Point的类和方法进行重命名。
那么这个入口点怎么来呢?就是从ProGuard的配置文件来,只要这个配置了,那么就不会被移除。
编写ProGuard文件的步骤:
- 基本混淆
- 针对APP的量身定制
- 针对第三方jar包的解决方案
基本混淆
混淆文件的基本配置信息,任何APP都要使用,可以作为模板使用
1.基本指令
# 代码混淆压缩比,在0和7之间,默认为5,一般不需要改
-optimizationpasses 5
# 混淆时不使用大小写混合,混淆后的类名为小写
-dontusemixedcaseclassnames
# 指定不去忽略非公共的库的类
-dontskipnonpubliclibraryclasses
# 指定不去忽略非公共的库的类的成员
-dontskipnonpubliclibraryclassmembers
# 不做预校验,preverify是proguard的4个步骤之一
# Android不需要preverify,去掉这一步可加快混淆速度
-dontpreverify
# 有了verbose这句话,混淆后就会生成映射文件
# 包含有类名->混淆后类名的映射关系
# 然后使用printmapping指定映射文件的名称
-verbose
-printmapping proguardMapping.txt
# 指定混淆时采用的算法,后面的参数是一个过滤器
# 这个过滤器是谷歌推荐的算法,一般不改变
-optimizations !code/simplification/arithmetic,!field/*,!class/merging/*
# 保护代码中的Annotation不被混淆,这在JSON实体映射时非常重要,比如fastJson
-keepattributes *Annotation*
# 避免混淆泛型,这在JSON实体映射时非常重要,比如fastJson
-keepattributes Signature
//抛出异常时保留代码行号,在异常分析中可以方便定位
-keepattributes SourceFile,LineNumberTable
-dontskipnonpubliclibraryclasses用于告诉ProGuard,不要跳过对非公开类的处理。默认情况下是跳过的,因为程序中不会引用它们,有些情况下人们编写的代码与类库中的类在同一个包下,并且对包中内容加以引用,此时需要加入此条声明。
-dontusemixedcaseclassnames,这个是给Microsoft Windows用户的,因为ProGuard假定使用的操作系统是能区分两个只是大小写不同的文件名,但是Microsoft Windows不是这样的操作系统,所以必须为ProGuard指定-dontusemixedcaseclassnames选项2.保留
# 保留所有的本地native方法不被混淆
-keepclasseswithmembernames class * {
native <methods>;
}
# 保留了继承自Activity、Application这些类的子类
# 因为这些子类,都有可能被外部调用
# 比如说,第一行就保证了所有Activity的子类不要被混淆
-keep public class * extends android.app.Activity
-keep public class * extends android.app.Application
-keep public class * extends android.app.Service
-keep public class * extends android.content.BroadcastReceiver
-keep public class * extends android.content.ContentProvider
-keep public class * extends android.app.backup.BackupAgentHelper
-keep public class * extends android.preference.Preference
-keep public class * extends android.view.View
-keep public class com.android.vending.licensing.ILicensingService
# 如果有引用android-support-v4.jar包,可以添加下面这行
-keep public class com.xxxx.app.ui.fragment.** {*;}
# 保留在Activity中的方法参数是view的方法,
# 从而我们在layout里面编写onClick就不会被影响
-keepclassmembers class * extends android.app.Activity {
public void *(android.view.View);
}
# 枚举类不能被混淆
-keepclassmembers enum * {
public static **[] values();
public static ** valueOf(java.lang.String);
}
# 保留自定义控件(继承自View)不被混淆
-keep public class * extends android.view.View {
*** get*();
void set*(***);
public <init>(android.content.Context);
public <init>(android.content.Context, android.util.AttributeSet);
public <init>(android.content.Context, android.util.AttributeSet, int);
}
# 保留Parcelable序列化的类不被混淆
-keep class * implements android.os.Parcelable {
public static final android.os.Parcelable$Creator *;
}
# 保留Serializable序列化的类不被混淆
-keepclassmembers class * implements java.io.Serializable {
static final long serialVersionUID;
private static final java.io.ObjectStreamField[] serialPersistentFields;
private void writeObject(java.io.ObjectOutputStream);
private void readObject(java.io.ObjectInputStream);
java.lang.Object writeReplace();
java.lang.Object readResolve();
}
# 对于R(资源)下的所有类及其方法,都不能被混淆
-keep class **.R$* {
*;
}
# 对于带有回调函数onXXEvent的,不能被混淆
-keepclassmembers class * {
void *(**On*Event);
}3.定制
# 保留实体类和成员不被混淆(对于实体,保留它们的set和get方法,对于boolean型get方法,有人喜欢命名isXXX的方式)
-keep public class com.xxxx.entity.** {
public void set*(***);
public *** get*();
public *** is*();
}
# 保留内嵌类不被混淆(内嵌类经常会被混淆,结果在调用的时候为空就崩溃了,最好的解决方法就是把这个内嵌类拿出来,单独成为一个类。如果一定要内置,那么这个类就必须在混淆的时候保留,$符号用来分割内嵌类与其母体的标志。)
-keep class com.example.xxx.MainActivity$* { *; }
# 对WebView的处理
-keepclassmembers class * extends android.webkit.webViewClient {
public void *(android.webkit.WebView, java.lang.String, android.graphics.Bitmap);
public boolean *(android.webkit.WebView, java.lang.String)
}
-keepclassmembers class * extends android.webkit.webViewClient {
public void *(android.webkit.webView, java.lang.String)
}
# 保留JS方法不被混淆(JSInterface是MainActivity的子类)
-keepclassmembers class com.example.xxx.MainActivity$JSInterface1 {
<methods>;
}4.处理反射
在程序中使用SomeClass.class.method这样的静态方法,在ProGuard中是在压缩过程中被保留的,那么对于Class.forName(“SomeClass”)呢,SomeClass不会被压缩过程中移除,它会检查程序中使用的Class.forName方法,对参数SomeClass法外开恩,不会被移除。但是在混淆过程中,无论是Class.forName(“SomeClass”),还是SomeClass.class,都不能蒙混过关,SomeClass这个类名称会被混淆,因此,我们要在ProGuard.cfg文件中保留这个类名称。在混淆的时候,要在项目中搜索一下上述方法,将相应的类或者方法的名称进行保留而不被混淆。
Class.forName("SomeClass")
SomeClass.class
SomeClass.class.getField("someField")
SomeClass.class.getDeclaredField("someField")
SomeClass.class.getMethod("someMethod", new Class[] {})
SomeClass.class.getMethod("someMethod", new Class[] { A.class })
SomeClass.class.getMethod("someMethod", new Class[] { A.class, B.class })
SomeClass.class.getDeclaredMethod("someMethod", new Class[] {})
SomeClass.class.getDeclaredMethod("someMethod", new Class[] { A.class })
SomeClass.class.getDeclaredMethod("someMethod", new Class[] { A.class, B.class })
AtomicIntegerFieldUpdater.newUpdater(SomeClass.class, "someField")
AtomicLongFieldUpdater.newUpdater(SomeClass.class, "someField")
AtomicReferenceFieldUpdater.newUpdater(SomeClass.class, SomeType.class, "someField")5.自定义View
但凡在Layout目录下的XML布局文件配置的自定义View,都不能进行混淆。为此要遍历Layout下的所有的XML布局文件,找到那些自定义View,然后确认其是否在ProGuard文件中保留。有一种思路是,在我们使用自定义View时,前面都必须加上我们的包名,比如com.a.b.customeview,我们可以遍历所有Layout下的XML布局文件,查找所有匹配com.a.b的标签即可。
第三方jar包
我们在Android项目中不可避免要使用很多第三方提供的SDK,一般而言,这些SDK是经过ProGuard混淆的,而我们所需要做的就是避免这些SDK的类和方法在我们APP被混淆。
1.针对android-support-v4.jar的解决方案
# 针对android-support-v4.jar的解决方案
-libraryjars libs/android-support-v4.jar
-dontwarn android.support.v4.**
-keep class android.support.v4.** { *; }
-keep interface android.support.v4.app.** { *; }
-keep public class * extends android.support.v4.**
-keep public class * extends android.app.Fragment2.其他的第三方jar包的解决方案
取决于第三方包的混淆策略,一般都有在各自的SDK中有关于混淆的说明文字,比如支付宝,值得注意的是,不是每个第三方SDK都需要-dontwarn 指令,这取决于混淆时第三方SDK是否出现警告,需要的时候再加上。
# 对alipay的混淆处理
-libraryjars libs/alipaysdk.jar
-dontwarn com.alipay.android.app.**
-keep public class com.alipay.** { *; }注意事项
1.如何确保混淆不会对项目产生影响
测试工作要基于混淆包进行,才能尽早发现问题
每天开发团队的冒烟测试,也要基于混淆包
发版前,重点的功能和模块要额外的测试,包括推送,分享,打赏
2.打包时忽略警告
当导出包的时候,发现很多could not reference class之类的warning信息,如果确认App在运行中和那些引用没有什么关系,可以添加-dontwarn 标签,就不会提示这些警告信息了
3.对于自定义类库的混淆处理
比如我们引用了一个叫做AndroidLib的类库,我们需要对Lib也进行混淆,然后在主项目的混淆文件中保留AndroidLib中的类和类的成员。
4.使用annotation避免混淆
另一种类或者属性被混淆的方式是,使用annotation
@keep
@keepPublicGetterSetters
public class Bean{
public boolean booleanProperty;
public int intProperty;
public String stringProperty;
}5.在项目中指定混淆文件
到最后,发现没有介绍如何在项目中指定混淆文件。在项目中有一个project.properties文件,在其中写这么一句话,就可以确保每次手动打包生成的apk是混淆过的。
proguard.config=proguard.cfg
其中,proguard.cfg是混淆文件的名称。
Native
JNI
- 定义:Java Native Interface,即 Java本地接口
- 作用:使得Java与本地其他类型语言(如C、C++)交互,即在Java代码里调用C、C++等语言的代码或C、C++代码调用 Java 代码
- 特性:
- JNI是Java调用Native语言的一种特性
- JNI是属于Java的,与Android无直接关系
- 实现:
- 在Java中声明Native方法(即需要调用的本地方法)
- 编译上述Java源文件javac(得到 .class文件)
- 通过javah命令导出JNI的头文件(.h文件)
- 使用Java需要交互的本地代码实现在Java中声明的Native方法,如Java需要与C++交互,那么就用C++实现Java的Native方法
- 编译.so库文件
- 通过Java命令执行 Java程序,最终实现Java调用本地代码
在JNI_OnLoad中注册
jint JNI_OnLoad(JavaVM* vm, void* reserved) {
//添加JNINativeMethod方法
static const JNINativeMethod gMethods[] = {
{"getUrl", "()Ljava/lang/String;", (jstring*)getUrl},
{"setData","([BI)V",(void*)setData}
};
//注册
static string className = "path/to/className";
gJavaVM = vm;
JNIEnv* env = NULL;
if ((*vm)->GetEnv(vm, (void**) &env, JNI_VERSION_1_6) != JNI_OK) {
return -1;
}
assert(env != NULL);
jclass clazz = (*env)->FindClass(env, className);
if (clazz == NULL) {
return -1;
}
if ((*env)->RegisterNatives(env, clazz, gMethods, numMethods) < 0) {
return -1;
}
return JNI_VERSION_1_6;
}NDK
- 定义:Native Development Kit,是 Android的一个工具开发包,NDK是属于Android的,与Java并无直接关系
- 作用:快速开发C、C+ * 作用:快速开发C、C+ * 作用:快速开发C、C++的动态库,并自动将so和应用一起打包成APK。即可通过NDK在Android中使用JNI与本地代码(如C、C++)交互
- 实现:
- 配置Android NDK环境
- 创建Android项目,并与NDK进行关联
- 在Android 项目中声明所需要调用的Native方法
- 使用Android需要交互的本地代码实现在Android中声明的Native方法,比如 Android 需要与C++交互,那么就用C++实现Java的Native方法
- 通过 ndk - bulid 命令编译产生.so库文件
- 编译 Android Studio工程,从而实现Android 调用本地代码
Gradle的配置
Module的gradle文件:
apply plugin: 'com.android.library'
apply from: "${project.rootDir}/config/maven_push.gradle"
android {
compileSdkVersion 28
buildToolsVersion "28.0.3"
defaultConfig {
minSdkVersion 14
targetSdkVersion 28
ndk{
moduleName "framework"
}
}
buildTypes {
release {
minifyEnabled false//缩减字符的混淆-针对java层
}
}
...
}
task clearJar(type: Delete) {
delete "build/outputs/libs/"
}
def getVersionName() {
return project.ext.mCurVersion
}
task makeJar(type: ProGuardTask, dependsOn: "build") {
// 未混淆的jar路径
injars 'build/intermediates/packaged-classes/release/classes.jar'
// 混淆后的jar输出路径
outjars "build/outputs/libs/efun-utils-${getVersionName()}.jar"
// 混淆协议
configuration 'proguard-rules.pro'
}
task makeJar(type: Copy) {
from('build/intermediates/packaged-classes/release/')
into('build/outputs/libs/')
include('classes.jar')
rename ('classes.jar', "efun-task-${getVersionName()}.jar")
}
ext.ndk = 'ndk'
task localProperty {
//注意:指定NDK实质路径是通过local.properties文件中的为准(也可以在project struct中设置-cmd+;)
ndk = "/Path/to/android-ndk-r18b/ndk-build"
}
task buildJni << {
System.out.println("ndk:"+ndk);
exec {
commandLine ndk
}
}
preBuild.dependsOn buildJniMake的配置
在Linux下编译经常要写一个Makefile文件, 可以把这个Makefile文件理解成一个编译配置文件,它保存着如何编译的配置信息,即指导编译器如何来编译程序,并决定编译的结果是什么。
而Android.mk文件是针对Android的Makefile文件,该文件是GNU Makefile的一小部分,会被编译系统解析一次或多次。可以在每一个Android.mk file中定义一个或多个模块,你也可以在几个模块中使用同一个源代码文件。编译系统为你处理许多细节问题。
LOCAL_PATH := $(call my-dir)
include $(CLEAR_VARS)
LOCAL_LDLIBS += -L$(SYSROOT)/usr/lib -llog
LOCAL_MODULE := efunframework-3.0
LOCAL_SRC_FILES := certificate.c \
md5.c \
secret_key.c \
include $(BUILD_SHARED_LIBRARY)- 首先必须定义好
LOCAL_PATH变量。然后清除所有LOCAL_XX变量的值。 - 宏函数
my-dir, 由编译系统提供,用于返回当前路径(即包含Android.mk file文件的目录)。 - 宏
CLEAR_VARS由编译系统提供,指定让GNU MAKEFILE为你清除许多LOCAL_XXX变量,因为所有的编译控制文件都在同一个GNU MAKE执行环境中,所有的变量都是全局的。 - LOCAL_SRC_FILES:是本次需要编译的源文件。
- LOCAL_SHARED_LIBRARIES:是本次编译需要链接的动态链接库文件,即.so文件。
- LOCAL_STATIC_LIBRARIES:是本次编译要链接的静态链接库。
- LOCAL_LDLIBS:是本次编译的链接选项,相当于gcc -l后的参数。
- LOCAL_CFLAGS:同样是编译选项,相当于gcc -O后面的参数。
- LOCAL_MODULE:是生成的模块名,这个变量必须定义,表示make后将要生成的文件的名字。
- include:多以这样的形式出现,如:include $( CLEAR_VARS)、include $(BUILD_SHARED_LIBRARY),其实这个include可以理解成”执行”的意思,比如清除一些变量、生成共享库,即生成.so文件。
选择打包包含的 cpu 架构
defaultConfig {
applicationId "com.xxx.xxxx"
minSdkVersion xx
targetSdkVersion xx
versionCode x
versionName "x.x"
ndk {
abiFilters 'armeabi-v7a' //只生成armv7的so
}
}AAR & JAR
使用Android Studio对工程进行编译后,会同时生成jar与aar文件。
位置
jar: /build/intermediates/bundles/debug(release)/classes.jar
aar: /build/outputs/aar/libraryname.aar区别
- jar 中只包含了class文件与清单文件。
- aar中除了包含jar中的class文件还包含工程中使用的所有资源,class及res资源文件全部包含。
如果只是一个简单的类库那么使用生成的* .jar文件即可;如果你的是一个UI库,包含一些自己写的控件布局文件以及字体等资源文件那么就只能使用*.aar文件。
使用
jar 拷贝到 libs 目录,并在gradle文件中添加
dependencies {
compile fileTree(include: ['*.jar'], dir: 'libs')
implementation fileTree(include: ['*.jar'], dir: 'libs') //gradle 3.0+
}aar 有两种方式:
本地使用:拷贝到libs目录,并在gradle文件中添加
repositories { flatDir { dirs 'libs' } } dependencies { compile(name:'genius', ext:'aar') }网络加载:将aar发布到mavenCentral仓库,在gradle文件中添加
repositories { maven { url "http://xxx.com/project" } } dependencies { classpath 'com.android.tools.build:gradle:3.2.1' }
多层Module依赖本地AAR
Android Studio多层Module依赖本地AAR,在编译的时候出发生错误,找不到AAR(ModuleA libs中有c.aar,ModuleB依赖ModuleA)
此时需要在ModuleB的build.gradle中添加
repositories {
flatDir {
dirs '../ModuleA/libs','libs'
}
}同时在dependencies中添加aar名称
compile(name:'c', ext:'aar')so加固
so:shared object,即是由系统动态加载的共享目标文件。
- 破坏ELF header或者删除Section header
- 对要保护的so函数或者section进行加密,把解密函数放到另外一个so中
- 自定义的section并加密,load so库时在main函数之前把自定义section解密
- NDK编译工具中可以集成LLVM-Obfuscator,需要修改交叉工具链的代码和一些配置参数,混淆代码
JVM
java -server -Xms3550M -Xmx3550M -XX:ReservedCodeCacheSize=1024m -jar apktool_2.4.0.jar b ‘Path/to/unzip/document’
-client,-server
这两个参数用于设置虚拟机使用何种运行模式,client模式启动比较快,但运行时性能和内存管理效率不如server模式,通常用于客户端应用程序。相反,server模式启动比client慢,但可获得更高的运行性能。
在 windows上,缺省的虚拟机类型为client模式,如果要使用 server模式,就需要在启动虚拟机时加-server参数,以获得更高性能,对服务器端应用,推荐采用server模式,尤其是多个CPU的系统。在 Linux,Solaris上缺省采用server模式。
-Xms
设置虚拟机可用内存堆的初始大小,缺省单位为字节,该大小为1024的整数倍并且要大于1MB,可用k(K)或m(M)为单位来设置较大的内存数。初始堆大小为2MB。
例如:-Xms6400K,-Xms256M
-Xmx
设置虚拟机内存堆的最大可用大小,缺省单位为字节。该值必须为1024整数倍,并且要大于2MB。可用k(K)或m(M)为单位来设置较大的内存数。缺省堆最大值为64MB。
例如:-Xmx81920K,-Xmx80M
当应用程序申请了大内存运行时虚拟机抛出java.lang.OutOfMemoryError: Java heap space错误,就需要使用-Xmx设置
The -X options are non-standard and subject to change without notice.
输入指令 java -X 查看
https://xinklabi.iteye.com/blog/837435
Res (Resource)
Res 就是指 app 或 library 两种 module 下面 res 路径下的所有资源,如下所示
├── app / library
│ ├── ...
│ └── src
│ │ ├── ...
│ │ └── main
│ │ │ ├── ...
│ │ │ └── resAndroid 在打包时,通过AAPT工具,对主工程和引入的依赖里的所有资源文件进行编译压缩,并会对res/里的资源文件如drawable、layout、values等生成唯一的id,同时生成R.java文件,保存所有的id值,以及生成resource.arsc文件,建立id对应资源的值(如string)或文件路径(如png)的关系表,R.java 文件如下
public final class R {
public static final class style {
public static final int xx_style = 0x7f050000;
...
}
public static final class string {
public static final int xx_string = 0x7f040000;
...
}
public static final class layout {
public static final int xx_layout = 0x7f030000;
...
}
public static final class id {
public static final int xx_id = 0x7f010000;
...
}
}resources.arsc 包含了全部的资源名称、资源 ID 和资源的内容,对于单独文件类型的资源,这个内容代表的是这个文件在其 .apk 文件中的路径信息,这样就把运行环境中的资源 ID 和具体的资源对应了起来。
在调试的时候,可以使用 “aapt dump resources <apk的路径>” 来看对 resources.arsc 文件的详细描述信息。
关于二进制资源表的详细定义在 resources数据结构的定义头文件里面。
资源分类:
animator ->属性动画
anim ->补间动画
color ->颜色资源
drawable ->图片资源
layout ->布局资源
menu ->菜单资源
raw ->任意格式资源(它同assets下资源一样会原封不动的打入APK文件中,不过它会被赋予ID)
values ->描述一些简单资源
xml ->描述应用程序的配置信息资源
// 使用示例
Resources res = getResources();
InputStream is = res.openRawResource(R.raw.filename);
// 上述9种类型资源,除了raw类型资源和Bitmap文件的drawable类型资源外,其余的资源都将在打包过程中编译成二进制格式的xml文件。
// 这些二进制文件分别有一个字符串资源池,用来保存文件中引用到的资源,使文件占用更小以及解析速度更快。
// 打包时除了assets和res/raw资源被原封不动打进APK之外,其他资源会被编译成二进制文件打进APK。
// 应用程序可以通过 AssetManager 来访问资源,或通过资源ID访问,或通过文件名访问。最终 R 文件会按类型分为不同的类,在不同包名下会有不同的 R 文件(每个 module 中的 AndroidManifest 的 package 决定着该 R 所属的包路径),而所有资源 ID 都是16进制的 int 值(32bit的数字),变量名就是我们在资源文件中定义的资源名字。
资源 ID 的组成:
- 第一个字节是指资源所属包,7F代表普通应用程序
- 第二个字节是指资源的类型,如02指drawable,03指layout
- 第三四个字节是指资源的编号,往往从00开始递增
格式是PPTTNNNN,PP代表资源所属的包(package),TT代表资源的类型(type),NNNN代表这个类型下面的资源的名称。对于应用程序的资源来说,PP的取值是0×77。TT 和 NNNN 的取值是由 AAPT 工具随意指定的,基本上每一种新的资源类型的数字都是从上一个数字累加的(从1开始),而每一个新的资源条目也是从数字1开始向上累加的。
由于 Java 编译器的优化,在编译时,所有使用静态常量的地方,会被直接替换为常量值。
这样一来,R 文件里的 ID 在编译完 java 文件后,就没有被引用的地方了,此时如果开启 proGuard 混淆,就会删除整个R文件,从而会减少 field 数和包大小。
资源冲突的问题
Android Studio 对模块化开发提供的一个很有用的功能就是可以在主项目下新建库项目(Module),但是在使用库项目时却有一个问题就是资源ID冲突,因为编译时SDK会自动帮我们处理这个问题,所以一般我们不会察觉到,但是在某些情况下,我们需要意识到这个问题的存在。
AAR 是被主工程引入的 SDK,一个工程可能会引入多个 AAR,这也就导致了一个问题:每个 AAR 的 module 如果在自己编译生成 AAR 时,按照正常的流程生成R文件,那么由于资源 ID 的值都是从00递增,会导致集成到主工程时的冲突(大量 ID 重复)。所以其实 AAR 在编译时不会进行真正的R.java文件的生成,而是等到在主工程集成编译时统一进行所有资源的id分配。
如果不同的 AAR 中有同类型的同名资源,则可能会在运行中有很多莫名其妙的问题,所以我们需要保证资源名的唯一性,特别是做 SDK 的。
AAR 做了两个工作:
- 为了支持我们的调用语法,在 AAR 包名下生成了一个 R.java 文件,而 AAR 生成的 R 文件里的 ID,并不是
public static final的常量,而是public static的变量,使编译时调用的地方先不要被替换为常量值,这些 AAR 里的资源 ID 只是临时的,等待主工程编译时再修改。 - 因为 AAR 生成的 R.java 并不是最终正确的,所以这个 R.java 文件不会被带入 AAR中,但是会生成一个 R.txt 文本文件,以便于主工程打包时,可以依据这些资源信息统一生成最终的 R.java 文件(我们整合 fat AAR 的时候其实可以忽略这个 R.txt)
主工程做了三个工作:
- 编译时,将主工程下的所有资源,连同所有 AAR 依赖里的 R.txt 文件一起(没有则找 AAR 里的所有资源),为所有的资源统一分配 ID,并生成最终的 R.java 文件和 resource.arsc 文件,这时就可以保证每个资源都是唯一的 ID 值。
- 最终除了会在主工程包名下,生成一个包含主工程和 AAR 所有资源的R.java文件之外,还会在每个 AAR 相应的包名下,生成一个包含AAR资源的R.java文件,相同资源的 ID 是一样的,我们在主工程中调用主包名的 R 文件,和 AAR 包名的 R 文件,都可以获取到一些资源 ID。
- 最终生成的所有 R.java 文件里的 ID 值,都是public static final的静态常量,因为此刻的 ID 值都已经确定了。在编译 java 文件时,常量值会被替换(包括资源文件中的引用也会被替换),从而使R文件的field无引用,可以通过 proGuard 删除。
注意:AAR里面的文件,使用到资源id的地方,并没有被替换为相应的常量值,但是R文件里面的资源 ID 是常量,这是因为 AAR 的 class 文件,在主工程编译时,不会再次进行编译,也就是说 AAR 的 class 文件原封不动的打包进apk(类似 iOS 中的 .a 文件一样,已经过预编译,直接链接即可),所以 AAR 包名下的 R 文件就会被保留下来。
但有 gradle 插件可将所有 AAR 中引用到R文件资源 ID 的地方,全部都替换为相应的 ID 常量值,然后在 proGuard 混淆时,所有的 R 文件就会因为没有被引用到而删除了。
自定义资源:
在Android资源中,有一种资源类型称为Public,一般定义在 res/values/public.xml 文件中
<?xml version="1.0" encoding="utf-8"?>
<resources>
<!--在宿主中指定这些id的范围是为了使宿主各类资源的id和插件各类资源的id不重复,否则会出错(若没出错也仅是凑巧)-->
<!-- 单独指定属性的资源范围是为了支持主题属性换肤 将end值设置为0100,意思预留从0000到0100的id给插件属性使用
即插件的attr不可超过256个,这个值可以根据实际情况调整
-->
<public-padding type="attr" name="public_static_final_host_attr_" start="0x7f010000" end="0x7f010100" />
<!-- 除属性外 其他类型的资源设置为 0x7f32开始 -->
<public-padding type="drawable" name="public_static_final_host_drawable_" start="0x7f320000" end="0x7f320000" />
<public-padding type="layout" name="public_static_final_host_layout_" start="0x7f330000" end="0x7f330000" />
<public-padding type="anim" name="public_static_final_host_anim_" start="0x7f340000" end="0x7f340000" />
<public-padding type="xml" name="public_static_final_host_xml_" start="0x7f350000" end="0x7f350000" />
<public-padding type="raw" name="public_static_final_host_raw_" start="0x7f360000" end="0x7f360000" />
<public-padding type="dimen" name="public_static_final_host_dimen_" start="0x7f370000" end="0x7f370000" />
<public-padding type="string" name="public_static_final_host_string_" start="0x7f380000" end="0x7f380000" />
<public-padding type="style" name="public_static_final_host_style_" start="0x7f390000" end="0x7f390000" />
<public-padding type="color" name="public_static_final_host_color_" start="0x7f3a0000" end="0x7f3a0000" />
<public-padding type="id" name="public_static_final_host_id_" start="0x7f3b0000" end="0x7f3b0000" />
<public-padding type="bool" name="public_static_final_host_bool_" start="0x7f3c0000" end="0x7f3c0000" />
<public-padding type="integer" name="public_static_final_host_int_" start="0x7f3d0000" end="0x7f3d0000" />
<public-padding type="array" name="public_static_final_host_array_" start="0x7f3e0000" end="0x7f3e0000" />
<public-padding type="menu" name="public_static_final_host_menu_" start="0x7f3f0000" end="0x7f3f0000" />
<public-padding type="mipmap" name="public_static_final_host_mipmap_" start="0x7f400000" end="0x7f400000" />
<public-padding type="animator" name="public_static_final_host_animator" start="0x7f410000" end="0x7f410000" />
<public-padding type="fraction" name="public_static_final_host_fraction" start="0x7f420000" end="0x7f420000" />
<public-padding type="font" name="public_static_final_host_font" start="0x7f430000" end="0x7f430000" />
<public-padding type="plurals" name="public_static_final_host_plurals" start="0x7f440000" end="0x7f440000" />
<public-padding type="interpolator" name="public_static_final_host_interpolator" start="0x7f450000" end="0x7f450000" />
<public-padding type="transition" name="public_static_final_host_transition" start="0x7f460000" end="0x7f460000" />
<public-padding type="_aapt" name="public_static_final_host__aapt" start="0x7f470000" end="0x7f470000" />
</resources>- type 用于指定资源类型
- name 用于appt在编译时重赋资源的name名称,name_资源名
- start 取值起始位置
- end 取值结束位置
每当 aapt 重新编译被修改过的资源时,都会重新给这些资源赋予 ID,即 AAPT 在每一次编译的时候不会去保存上一次生成的资源ID标示,每当 /res 目录发生变化的时候,AAPT 可能会去重新给资源指定 ID ,然后重新生成一个 R.java 文件。因此,在做开发的时候,你不应该在程序中将资源 ID 持久化保存到文件或者数据库。而资源 ID 在每一次编译后都有可能变化。
资源访问器 AssetManager
每个 Activity 都会关联一个 ContextImpl 对象,Activity 和 ContextImpl 都继承于Context,所以 Activity 大部分成员函数通过都调用 ContextImpl 对象的对应函数做处理的,其中访问程序资源是通过调用 ContextImpl 对象的 getResources() 和 getAssets() 函数来实现的:
- getResources():返回一个Resources对象,通过Resources对象我们就可以通过资源ID访问资源
- getAssets():返回一个AssetsManager对象,通过AssetsManager对象我们就可以通过文件名访问被编译过的资源文件
事实上 Resources 也是通过 AssetsManager 来访问资源文件的,只不过它会先通过资源ID查找到资源文件名,Resources 类中的成员函数 getAssets(),通过它可以获取 Resources 类中成员变量 mAssets 的 AssetsManager 对象,所以访问资源最终实现仍在 AssetsManager 实现。
Android系统允许一个进程中存在多个 apk 文件,每个APK文件都会有一个全局的 Resources 对象和 AssetsManager 对象,全局的 Resources 对象存储在对应的 ContextImpl 对象的成员变量 mResources 中,全局的 AssetsManager 对象存储在对应的 Resources 对象的成员变量 mAssets 中。
AssetsManager 的 C++ 层:
- AssetsManager 类除了 Java 层的实现外,还有C++层对应的实现。而Java层的 AssetsManager 类的功能就是通过C++层来实现的;
- Java 层每个 AssetsManager 对象都有一个 int 类型的成员变量 mObject,mObject保存的便是在 C++ 层对应的 AssetsManager 对象地址.
- 通过 mObject 这个变量可以将 Java 层对象和 C++ 层对象关联起来
- C++ 层的 AssetsManager 类有三个重要的成员变量
AssetsManager 的属性:
mAssetPaths -> 资源存放目录
mResources -> 指向一个资源索引表,以供Resources对象通过资源ID访问资源
mConfig -> 设备的本地配置信息,包括屏幕的密度和大小、国家地区、语言等
有了这三个变量后,C++层的AssetsManager类就可以访问程序资源了
Database
Android客户端的数据存储方式主要包括以下几种:
- SharePreferences:轻量级的数据存储,以键值对的形式存储数据,数据存储的格式为xml
- SQLite:Sql数据库
- Content Provider:Android提供的数据共享的一种功能,可以获取其他App的数据
- File文件存储:I/O文件存储;
- 网络存储。
典型数据库方面,除了SQLite,还有其它第三方框架可以选用,比如 ORM(Object Relation Mapping,对象关系映射)类型的数据库
|框架名称| 功能描述
|OrmLite| JDBC和Android的轻量级ORM java包
|Sugar| 用超级简单的方法处理Android数据库
|GreenDAO| 一种轻快地将对象映射到SQLite数据库的ORM解决方案,使用的App有:薄荷,京东
|ActiveAndroid| 以活动记录方式为Android SQLite提供持久化
|SQLBrite| SQLiteOpenHelper 和ContentResolver的轻量级包装
|Realm| 移动数据库:一个SQLite和ORM的替换品
|android-database-sqlcipher| 数据库加密
|storio| Beautiful API for SQLiteDatabase and ContentResolver
|realm-java| 高性能数据库
SQLite
具备的特点:
- 轻量级 使用 SQLite 只需要带一个动态库(也就是NDK开发的SO库),就可以享受它的全部功能,而且那个动态库的尺寸想当小,因此对于移动端的使用来说可谓是“百利而无一害”。
- 独立性 SQLite 数据库的核心引擎不需要依赖第三方软件,也不需要所谓的“安装”。
- 隔离性 SQLite 数据库中所有的信息(比如表、视图、触发器等)都包含在一个文件夹内,方便管理和维护,具体的表现形式就是每个数据库就是一个db文件,相当于库与库之前是彼此隔离的。
- 跨平台 SQLite 目前支持大部分操作系统,不只电脑操作系统更在众多的手机系统也是能够运行,比如:Android和IOS。
- 多语言接口 SQLite 数据库支持多语言编程接口(在Android端话一般会使用JDK或者NDK来开发)。
- 安全性 SQLite 数据库通过数据库级上的独占性和共享锁来实现独立事务处理。这意味着多个进程可以在同一时间从同一数据库读取数据,但只能有一个可以写入数据(涉及并发问题的处理方式类似于另一个关系型数据库-MySQL)。
- 弱类型的字段 同一列中的数据可以是不同类型(编码自由者的福音、编码强迫症的噩梦)
常用类型:
- NULL
- VARCHAR
- TEXT
- INTEGER
- BLOB
- CLOB
工具:
- 命令行方式:adb shell 进入后使用 sqlite 指令操作数据库,数据库位于 data/data/{packagename}/database/xx.db 下
- 可视化工具:SQLiteStudio、DB Browser for SQLite
应用:
一般使用 SQLiteDatabase 的辅助类 SQLiteOpenHelper 实现,其通过对SQLiteDatabase 内部方法的封装简化了数据库创建与版本管理的操作。它是一个抽象类,一般情况下,我们需要继承并重写这两个父类方法:
- onCreate 在初次生成数据库时才会被调用,我们一般重写onCreate生成数据库表结构并添加一些应用使用到的初始化数据。如果数据库不存在,会自动生成一个然后再调用此方法,否则不会调用此方法
- onUpgrade 当数据库版本有更新时会调用这个方法(当打开数据库时传入的版本号与当前的版本号不同时,只要某次创建SQLiteOpenHelper是指定的版本号高于之前的版本),我们一般会在这执行数据库更新的操作,例如字段更新、表的增加与删除等更新表结构
- 此外父类方法中还有onConfigure、onDowngrade、onOpen,一般项目中很少用到它们
SQLiteOpenHelper 提供了两个打开/获取创建数据库的方法,从源码上都是调用 getDatabaseLocked 实现: - getWritableDatabase:以写的方式打开数据库,注意:一旦数据库的磁盘空间满了或没权限,数据库就只能读不能写,使用该方法就会出错
- getReadableDatabase:以读写的方式打开数据库,如果数据库的磁盘空间满了,就会打开失败,当打开失败后会继续以只读的方法打开
SQLiteOpenHelper 无论获取多少次对象,都是同一个相同的对象,调用getWritableDatabase(),getReadableDatabase()的也是相同的实例,获取该对象后,就可以利用其操作数据库。
在 SQLiteDatabase 或 SQLiteOpenHelper,一般情况下我们在创建数据库时 path 参数只需传入“xxx.db”,系统自动会在该默认路径下创建名为“xxx.db”的数据库文件,这样做最大的好处就是安全,因为从Android7开始,Android的策略就限制了App彼此间的访问权限,这也使App的安全性得到了保证。默认路径:
/data/data/{package_name}/databases/1 继承 SQLiteOpenHelper
public class ApmDbManager extends SQLiteOpenHelper2 定义数据库名称及数据表名称
private final static String DATABASE_NAME = "database.db";
private final static String TABLE_NAME = "table";
private final static int DATABASE_VERSION = 1;3 创建指定版本的数据库实例
ApmDbManager instance = new ApmDbManager(context, DATABASE_NAME, DATABASE_VERSION);4 重写 onCreate
@Override
public void onCreate(SQLiteDatabase sqLiteDatabase) {
// 初始化数据库-创建表(若要限制字段长度,可 log_sign char(10))
sqLiteDatabase.execSQL("create table if not exists " + TABLE_NAME + " (id integer NOT NULL primary key autoincrement, tb text NOT NULL, log_time integer NOT NULL, log_type integer NOT NULL, log_sign text, log_index text, is_uploading integer)");
}5 重写 onUpgrade
@Override
public void onUpgrade(SQLiteDatabase sqLiteDatabase, int oldVersion, int newVersion) {
if (oldVersion < 2) {
sqLiteDatabase.execSQL("ALTER TABLE " + DATABASE_NAME + " ADD COLUMN log_new1 string;");
}
if (oldVersion < 3) {
sqLiteDatabase.execSQL("ALTER TABLE " + DATABASE_NAME + " ADD COLUMN log_new2 string;");
}
}这样,无论前一个版本是什么,也不管升级到的版本是什么,app将运行合适的语句使得app字段得到正确的更新。
注意,还需要在onCreate中的创建语句中进行更改,在更新中添加的字段,请将其同步添加到onCreate函数中的create语句,保持新老用户都有此新字段。
6 增删改查
/// 以下均使用自行SQL语句方式实现
// 增
SQLiteDatabase db = getWritableDatabase();
db.execSQL("insert into " + TABLE_NAME + " (tb, log_time, log_type, log_sign, log_index, is_uploading) values (?, ?, ?, ?, ?, ?)",
new Object[]{model.getTb(), model.getLogTime(), String.valueOf(type), model.getLogSign(), model.getLogIndex(), String.valueOf(model.isUploading())});
// 删
SQLiteDatabase db = getWritableDatabase();
db.execSQL("delete from " + TABLE_NAME + " where id = ?", new Object[]{model.getLogId()});
// 改
SQLiteDatabase db = getWritableDatabase();
db.execSQL("update " + TABLE_NAME + " set is_uploading = ? where id = ?", new Object[]{String.valueOf(isUploading), tableId});
// 查
SQLiteDatabase db = getReadableDatabase();
/// 获取游标
Cursor cursor = db.rawQuery("select * from " + TABLE_NAME + " where is_uploading = ?", new String[]{String.valueOf(isUploading)});
if (cursor == null) {
//查找失败,或没有记录
}
if (cursor.moveToFirst()) {
// for 循环方式:for(cursor.moveToFirst();!cursor.isAfterLast();cursor.moveToNext())
do{
// 创建模型对象
...
// 获取字段值
model.setLogId(cursor.getInt(cursor.getColumnIndex("id")))
// 其它cursor方法
cursor.moveToPosition(position);
cursor.getColumnName(columnIndex);
cursor.moveToLast();
cursor.getColumnCount();
cursor.getCount();
cursor.getColumnNames();
cursor.isClosed();
}while(cursor.moveToNext());
// 返回模型对象集合
...
} else {
//查找失败,或没有记录
}
cursor.close();
/// SQLiteDatabase 有提供现成的 insert、delete、update、query 的 api
// 增,返回该行的主键,如果出错返回-1
ContentValues cv = new ContentValues();
cv.put("name", "xx");
cv.put("money", 10000);
long i = db.insert("person", null, cv);
// 改
ContentValues cv = new ContentValues();
cv.put("money", 25000);
int i = db.update("person", cv, "name = ?", new String[]{"xx"});
// 删
int i = db.delete("person", "_id = ? and name = ?", new String[]{"1", "xx"});
// 查
db.query(table, columns, selection, selectionArgs, groupBy, having, orderBy, limit);
///table 表名
//columns 查询的字段
//selection 查询条件
//selectionArgs 填充查询条件的占位符,条件中?对应的值
//groupBy 分组查询参数
//having 分组查询条件
//orderBy 排序字段和规则,“字段名 desc/asc”
//limit 分页查询,“m,n”,m表示从第几条开始查,n表示一个查询多少条数据7 事务优化
SQLiteDatabase db = getWritableDatabase();
db.beginTransaction();
try{
//批量处理操作
for (SomeModel model : models) {
db.execSQL("delete from " + TABLE_NAME + " where id = ?", new Object[]{model.getLogId()});
}
//设置事务标志为成功,当结束事务时就会提交事务
db.setTransactionSuccessful();
}
catch(Exception e){
}
finally {
//结束事务
db.endTransaction();
}使用 SQLiteDatabase 的 beginTransaction() 方法可以开启一个事务,程序执行到 endTransaction() 方法时会检查事务的标志是否为成功,如果程序执行到 endTransaction() 之前调用了setTransactionSuccessful() 方法设置事务的标志为成功则提交事务,如果没有调用 setTransactionSuccessful() 方法则回滚事务。
事务处理应用,很多时候我们需要批量的向Sqlite中插入大量数据时,单独的使用添加方法导致应用响应缓慢, 因为sqlite插入数据的时候默认一条语句就是一个事务,有多少条数据就有多少次磁盘操作。如初始8000条记录也就是要8000次读写磁盘操作。同时也是为了保证数据的一致性,避免出现数据缺失等情况。
注意:
- 结束事务的 endTransaction() 最好放在 try catch 的 finally 中执行,避免执行 sql 语句产生异常时无法关闭事务
- 事务最好不要应用到多线程的环境上,否则可能出现一个线程关闭了事务另一个线程还在写入数据。(或者加锁)
8 异步
可以实现一个异步的单线程任务队列,来执行 sql 语句,实现异步效果同时保障线程安全。具体参考下面关于线程的一章。类似的效果:
SingleThreadCachedScheduler executor = new SingleThreadCachedScheduler("SdkHandler");
executor.submit(new Runnable() {
@Override
public void run() {
SQLiteDatabase db = getWritableDatabase();
db.execSQL("insert into " + TABLE_NAME + " (tb, log_time, log_type, log_sign, log_index, is_uploading) values (?, ?, ?, ?, ?, ?)",
new Object[]{model.getTb(), model.getLogTime(), String.valueOf(type), model.getLogSign(), model.getLogIndex(), String.valueOf(model.isUploading())});
}
});参考:
SQLite - 维基百科,自由的百科全书
从FMDB线程安全问题说起
多线程下使用FMDB进行数据库访问和死锁问题 · Issue #4 · yuhanle/blogbag · GitHub
ORM 实例教程 - 阮一峰的网络日志
SQLiteOpenHelper | Android 开发者 | Android Developers
独家食用指南系列|Android端SQLite的浅尝辄止 - 知乎
Multiple threading questions when using sqlite transaction in Android - Stack Overflow
线程
异步单线程任务
使用队列(用数组模拟)实现。
创建队列:
private final List<Runnable> queue = new ArrayList<>();创建线程池:
- 指定 corePoolSize 为 0,同时指定 maximumPoolSize 为 Integer.MAX_VALUE,表示线程数几乎无限制。
- keepAliveTime = 60s,线程空闲60s后自动结束。
- workQueue 为 SynchronousQueue 同步队列,这个队列类似于一个接力棒,入队出队必须同时传递,因为CachedThreadPool线程创建无限制,不会有队列等待,所以使用SynchronousQueue。一般分为直接提交队列、有界任务队列、无界任务队列、优先任务队列:
- 直接提交队列 SynchronousQueue:一个特殊的BlockingQueue,它没有容量,没执行一个插入操作就会阻塞,需要再执行一个删除操作才会被唤醒,反之每一个删除操作也都要等待对应的插入操作。创建的线程数大于maximumPoolSize时,直接执行拒绝策略抛出异常。使用SynchronousQueue队列,提交的任务不会被保存,总是会马上提交执行。如果用于执行任务的线程数量小于maximumPoolSize,则尝试创建新的进程,如果达到maximumPoolSize设置的最大值,则根据你设置的handler执行拒绝策略。因此这种方式你提交的任务不会被缓存起来,而是会被马上执行,在这种情况下,你需要对你程序的并发量有个准确的评估,才能设置合适的maximumPoolSize数量,否则很容易就会执行拒绝策略;
- 有界的任务队列 ArrayBlockingQueue:若有新的任务需要执行时,线程池会创建新的线程,直到创建的线程数量达到corePoolSize时,则会将新的任务加入到等待队列中。若等待队列已满,即超过ArrayBlockingQueue初始化的容量,则继续创建线程,直到线程数量达到maximumPoolSize设置的最大线程数量,若大于maximumPoolSize,则执行拒绝策略。在这种情况下,线程数量的上限与有界任务队列的状态有直接关系,如果有界队列初始容量较大或者没有达到超负荷的状态,线程数将一直维持在corePoolSize以下,反之当任务队列已满时,则会以maximumPoolSize为最大线程数上限。
- 无界的任务队列 LinkedBlockingQueue:使用无界任务队列,线程池的任务队列可以无限制的添加新的任务,而线程池创建的最大线程数量就是你corePoolSize设置的数量,也就是说在这种情况下maximumPoolSize这个参数是无效的,哪怕你的任务队列中缓存了很多未执行的任务,当线程池的线程数达到corePoolSize后,就不会再增加了;若后续有新的任务加入,则直接进入队列等待,当使用这种任务队列模式时,一定要注意你任务提交与处理之间的协调与控制,不然会出现队列中的任务由于无法及时处理导致一直增长,直到最后资源耗尽的问题。
- 优先任务队列 PriorityBlockingQueue:除了第一个任务直接创建线程执行外,其他的任务都被放入了优先任务队列,按优先级进行了重新排列执行,且线程池的线程数一直为corePoolSize,也就是只有一个。无论添加了多少个任务,线程池创建的线程数也不会超过corePoolSize的数量,只不过其他队列一般是按照先进先出的规则处理任务,而PriorityBlockingQueue队列可以自定义规则根据任务的优先级顺序先后执行。
- threadFactory 指定线程工厂类,注意,这里的返回的线程有60秒的空闲时间限制,超出则被回收,下次有任务安排时就会重新创建线程,若队列中有多个任务排队,则这些任务会在同一个线程中完成。
- 拒绝策略
- AbortPolicy策略:该策略会直接抛出异常,阻止系统正常工作;
- CallerRunsPolicy策略:如果线程池的线程数量达到上限,该策略会把任务队列中的任务放在调用者线程当中运行;
- DiscardOledestPolicy策略:该策略会丢弃任务队列中最老的一个任务,也就是当前任务队列中最先被添加进去的,马上要被执行的那个任务,并尝试再次提交;
- DiscardPolicy策略:该策略会默默丢弃无法处理的任务,不予任何处理。当然使用此策略,业务场景中需允许任务的丢失;
- 自定义策略:以上内置的策略均实现了RejectedExecutionHandler接口,当然你也可以自己扩展RejectedExecutionHandler接口,定义自己的拒绝策略;
threadPoolExecutor = new ThreadPoolExecutor(
0,
Integer.MAX_VALUE,
60L,
TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
new ThreadFactory() {
@Override
public Thread newThread(Runnable runnable) {
Thread thread = Executors.defaultThreadFactory().newThread(runnable);
thread.setPriority(Process.THREAD_PRIORITY_BACKGROUND + Process.THREAD_PRIORITY_MORE_FAVORABLE);
thread.setName("thread-name");
thread.setDaemon(true);
thread.setUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() {
@Override
public void uncaughtException(@NonNull Thread thread, @NonNull Throwable throwable) {
Log.e(String.format("Thread [%s] with error [%s]", thread.getName(), throwable.getMessage()));
}
});
return thread;
}
},
// 采用自定义拒绝策略
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable runnable, ThreadPoolExecutor threadPoolExecutor) {
Log.e(String.format("Runnable [%s] rejected from [%s]", runnable.toString(), source));
}
});安排任务:
public void submit(Runnable task) {
// 阻塞其它线程调用该队列来放入任务
synchronized (queue) {
// 上个线程完成任务安排后,且任务执行完,可进行任务的安排及执行(重新分配线程),否则排队(会继续在正在执行的线程中执行)
if (!isThreadProcessing) {
isThreadProcessing = true;
processQueue(task);
}
else {
queue.add(task);
}
}
}执行任务:
private void processQueue(final Runnable firstRunnable) {
// 安排执行当前任务,线程池给任务分配新线程
threadPoolExecutor.submit(new Runnable() {
@Override
public void run() {
// 新线程开始执行任务(其它任务还在等下一步)
tryExecuteRunnable(firstRunnable);
// 当前线程下,按入队顺序(FIFO)继续执行剩余的其它任务
Runnable runnable;
while (true) {
synchronized (queue) {
if (queue.isEmpty()) {
isThreadProcessing = false;
break;
}
// FIFO
runnable = queue.get(0);
queue.remove(0);
}
tryExecuteRunnable(runnable);
}
}
});
}
private void tryExecuteRunnable(Runnable runnable) {
try {
runnable.run();
} catch (Throwable t) {
Log.e(String.format("Execution failed: %s", t.getMessage()));
}
}// 安排定时任务
public void schedule(final Runnable task, final long millisecondsDelay) {
synchronized (queue) {
threadPoolExecutor.submit(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(millisecondsDelay);
} catch (InterruptedException e) {
Log.e("Sleep delay exception: %s" + e.getMessage());
}
submit(task);
}
});
}
}参考:
java线程池ThreadPoolExecutor类使用详解 - bigfan - 博客园
存储目录
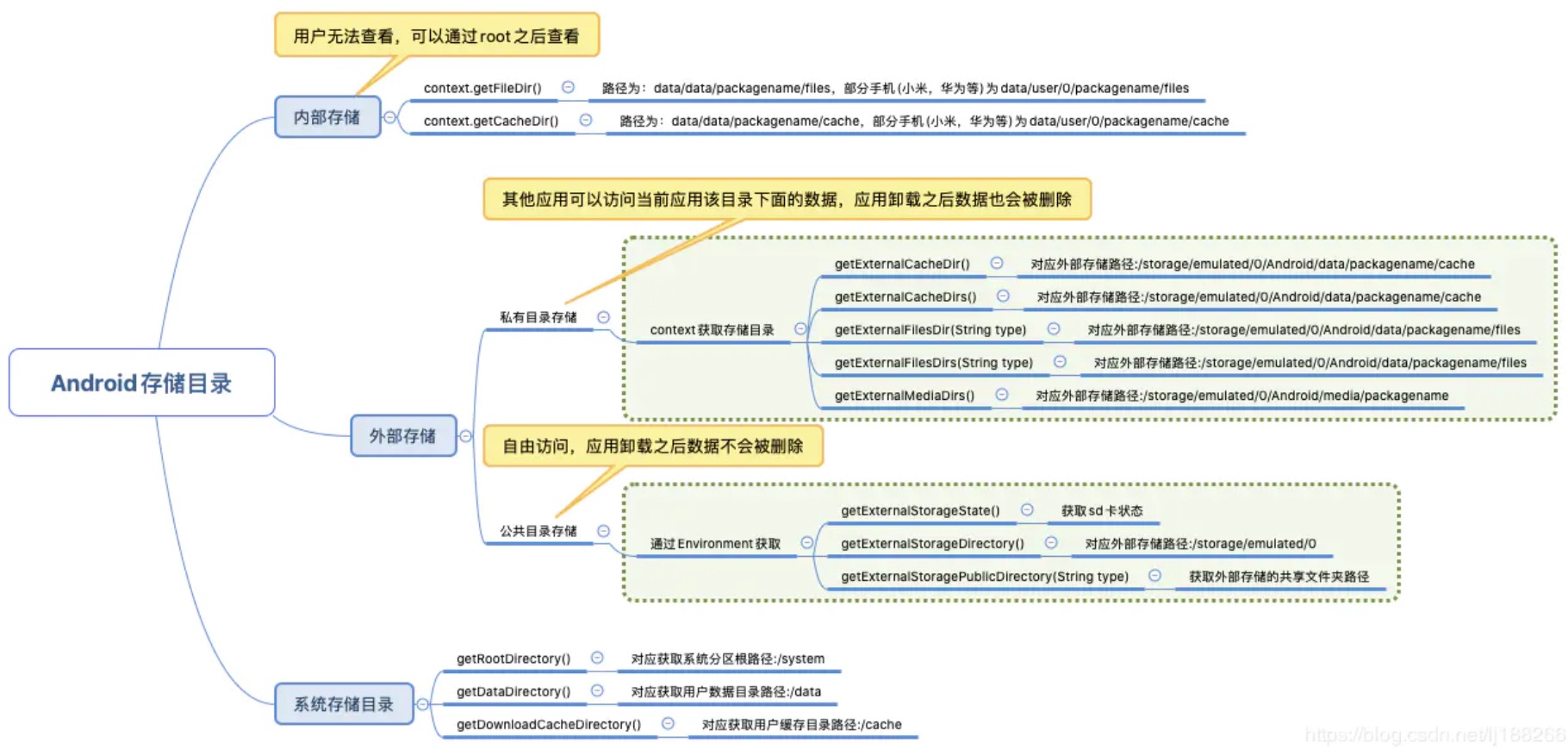
内部存储
内部存储位于系统中很特殊的一个位置,对于设备中每一个安装的 App,系统都会在 data/data/packagename/xxx 自动创建与之对应的文件夹,例如 sqlite 数据库。如果你想将文件存储于内部存储中,那么文件默认只能被你的应用访问到,且一个应用所创建的所有文件都在和应用包名相同的目录下。也就是说应用创建于内部存储的文件,与这个应用是关联起来的。当一个应用卸载之后,内部存储中的这些文件也被删除。对于这个内部目录,用户是无法访问的,除非获取root权限。
获取路径方法
String fileDir = context.getFilesDir().getAbsolutePath();
String cacheDir = context.getCacheDir().getAbsolutePath();getFilesDir 对应内部存储的路径为: data/data/packagename/files,但是对于有的手机如:华为,小米等获取到的路径为:data/user/0/packagename/files。
getCacheDir 对应内部存储的路径为: data/data/packagename/cache,但是对于有的手机如:华为,小米等获取到的路径为:data/user/0/packagename/cache,是应用程序的缓存目录,该目录内的文件在设备内存不足时会优先被删除掉,所以存放在这里的文件是没有任何保障的,可能会随时丢掉。
外部存储
Android4.4以前,手机机身存储就叫内部存储,插入的SD卡就是外部存储
Android4.4以后,手机机身自带的存储也是外部存储,如果再插入SD卡的话也叫外部存储,因此对于外部存储分为两部分:SD卡和扩展卡内存
对于前面提到的app下载升级功能,从服务器端下载的app需要放到外部存储目录下面,而不是内部存储目录,因为内部存储目录的空间很小。另外我也做了相关测试,如果将apk放到内部存储目录file下面的话,安装时会出现问题,提示解析包出错。
获取带有插入SD卡的各外部存储目录:
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.KITKAT) {
File[] files = getExternalFilesDirs(Environment.MEDIA_MOUNTED);
for (File file : files) {
Log.e("file_dir", file.getAbsolutePath());
}
}机身自带的外部存储目录结构为:/storage/emulated/0/Android/data/packagename/files
存储卡的目录结构为:/storage/extSdCard/Android/data/packagename/files
扩展外部存储
在 app 卸载之后,这些文件也会被删除。类似于内部存储。
String exFileDir = context.getExternalFilesDir().getAbsolutePath();
String exCacheDir = context.getExternalCacheDir().getAbsolutePath();getExternalFilesDir 对应外部存储路径:/storage/emulated/0/Android/data/packagename/files
getExternalCacheDir 对应外部存储路径:/storage/emulated/0/Android/data/packagename/cache
当授权应用存储权限时,就会创建出以上目录
SD卡存储
SD卡里面的文件是可以被自由访问,即文件的数据对其他应用或者用户来说都是可以访问的,当应用被卸载之后,其卸载前创建的文件仍然保留。
对于SD卡上面的文件路径需要通过Environment获取,同时在获取前需要判断SD的状态:
MEDIA_UNKNOWN SD卡未知
MEDIA_REMOVED SD卡移除
MEDIA_UNMOUNTED SD卡未安装
MEDIA_CHECKING SD卡检查中,刚装上SD卡时
MEDIA_NOFS SD卡为空白或正在使用不受支持的文件系统
MEDIA_MOUNTED SD卡安装
MEDIA_MOUNTED_READ_ONLY SD卡安装但是只读
MEDIA_SHARED SD卡共享
MEDIA_BAD_REMOVAL SD卡移除错误
MEDIA_UNMOUNTABLE 存在SD卡但是不能挂载,例如发生在介质损坏
String externalStorageState = Environment.getExternalStorageState();
if (externalStorageState.equals(Environment.MEDIA_MOUNTED)){
//sd卡已经安装,可以进行相关文件操作
}getExternalStorageDirectory 对应外部存储路径:/storage/emulated/0
getExternalStoragePublicDirectory(Environment.type) 获取外部存储的共享文件夹路径,type 包括:
- DIRECTORY_MUSIC 音乐目录
- DIRECTORY_PICTURES 图片目录
- DIRECTORY_MOVIES 电影目录
- DIRECTORY_DOWNLOADS 下载目录
- DIRECTORY_DCIM 相机拍照或录像文件的存储目录
- DIRECTORY_DOCUMENTS 文件文档目录
系统存储
- getRootDirectory() 对应获取系统分区根路径:/system
- getDataDirectory() 对应获取用户数据目录路径:/data
- getDownloadCacheDirectory() 对应获取用户缓存目录路径:/cache
问题集
error=13, Permission denied
在Mac的Android Studio IDE上,若提示该错误,可针对提示中的问题路径修改访问权限
chmod +x /Users/MyUserName/Library/Android/sdk/tools/android
chmod +x /Users/MyUserName/PathTo/Android/android-ndk-r18b
Android Studio真机调试返回 Entry name ‘assets/ae/res.ck‘ collided
调试应用宝 SDK 接入时,Android Studio编译成功,但是真机调试的时候返回标题所述错误。
解决方法:在 gradle.Properties 文件中增加配置 android.useNewApkCreator=false
You have not accepted the license agreements of the following SDK components
自动同意所有下载的SDK的license即可解决,
yes | sdkmanager –licenses
yes | sudo ~/Library/Android/sdk/tools/bin/sdkmanager –licenses
java.lang.RuntimeException: Can’t create handler inside thread that has not called Looper.prepare()
原因可能有以下:
- 在子线程中有某些地方做了UI操作,并没有放到 handler 中去执行。主线程不能做耗时操作,而子线程中不能做更改UI操作,需要通过主线程创建 handler 来做,注意是主线程创建的 handler。
- 在子线程中创建 handler。若要创建 handler(例如 okhttp 开始请求前),要不然让调用的子线程 Looper.prepare(),要不在主线程上发起
// 子线程中 Handler handler = new Handler(Looper.getMainLooper()); handler.post(new Runnable() { @Override public void run() { // new some handler ... } } activity.runOnUiThread(new Runnable() { public void run() { // new some handler ... } });
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 mingfungliu@gmail.com
文章标题:Android工程入门
文章字数:17.3k
本文作者:Mingfung
发布时间:2019-02-24, 13:44:00
最后更新:2022-01-13, 17:31:27
原始链接:http://blog.ifungfay.com/Android/Android工程入门/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

